 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing the Natural Language Inference Task with Automated Reasoning Tools
Paper and Code
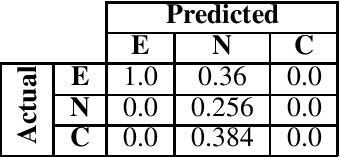

The Natural Language Inference (NLI) task is an important task in modern NLP, as it asks a broad question to which many other tasks may be reducible: Given a pair of sentences, does the first entail the second? Although the state-of-the-art on current benchmark datasets for NLI are deep learning-based, it is worthwhile to use other techniques to examine the logical structure of the NLI task. We do so by testing how well a machine-oriented controlled natural language (Attempto Controlled English) can be used to parse NLI sentences, and how well automated theorem provers can reason over the resulting formulae. To improve performance, we develop a set of syntactic and semantic transformation rules. We report their performance, and discuss implications for NLI and logic-based NLP.