 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Spurious Correlations in Popular Event-Based Rumor Detection Benchmarks
Paper and Code


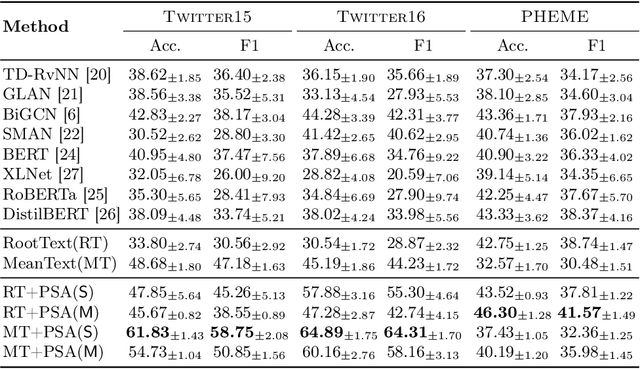

As social media becomes a hotbed for the spread of misinformation, the crucial task of rumor detection has witnessed promising advances fostered by open-source benchmark datasets. Despite being widely used, we find that these datasets suffer from spurious correlations, which are ignored by existing studies and lead to severe overestimation of existing rumor detection performance. The spurious correlations stem from three causes: (1) event-based data collection and labeling schemes assign the same veracity label to multiple highly similar posts from the same underlying event; (2) merging multiple data sources spuriously relates source identities to veracity labels; and (3) labeling bias. In this paper, we closely investigate three of the most popular rumor detection benchmark datasets (i.e., Twitter15, Twitter16 and PHEME), and propose event-separated rumor detection as a solution to eliminate spurious cues. Under the event-separated setting, we observe that the accuracy of existing state-of-the-art models drops significantly by over 40%, becoming only comparable to a simple neural classifier. To better address this task, we propose Publisher Style Aggregation (PSA), a generalizable approach that aggregates publisher posting records to learn writing style and veracity stance. Extensive experiments demonstrate that our method outperforms existing baselines in terms of effectiveness, efficiency and generalizability.