 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbability Distribution Alignment and Low-Rank Weight Decomposition for Source-Free Domain Adaptive Brain Decoding
Paper and Code
Apr 15, 2025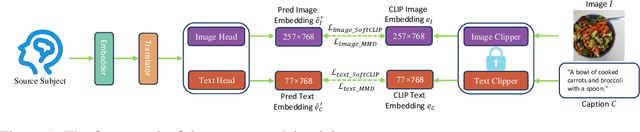


Brain decoding currently faces significant challenges in individual differences, modality alignment, and high-dimensional embeddings. To address individual differences, researchers often use source subject data, which leads to issues such as privacy leakage and heavy data storage burdens. In modality alignment, current works focus on aligning the softmax probability distribution but neglect the alignment of marginal probability distributions, resulting in modality misalignment. Additionally, images and text are aligned separately with fMRI without considering the complex interplay between images and text, leading to poor image reconstruction. Finally, the enormous dimensionality of CLIP embeddings causes significant computational costs. Although the dimensionality of CLIP embeddings can be reduced by ignoring the number of patches obtained from images and the number of tokens acquired from text, this comes at the cost of a significant drop in model performance, creating a dilemma. To overcome these limitations, we propose a source-free domain adaptation-based brain decoding framework.