 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy Re-identification Attacks on Tabular GANs
Paper and Code
Mar 31, 2024
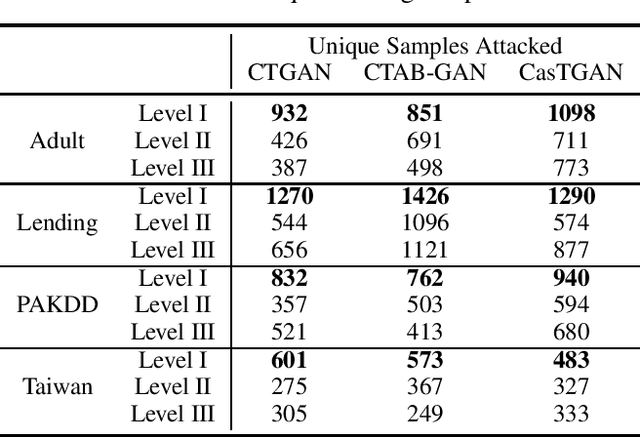
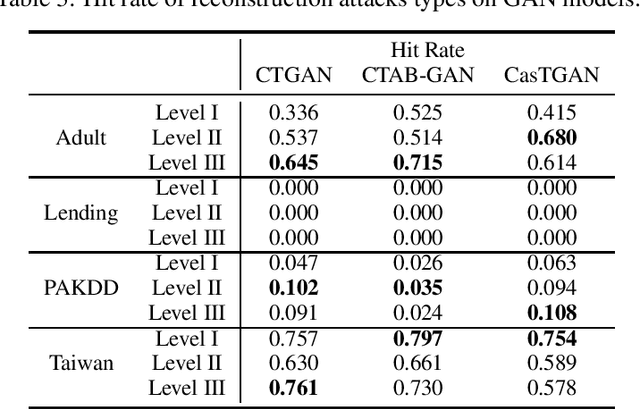
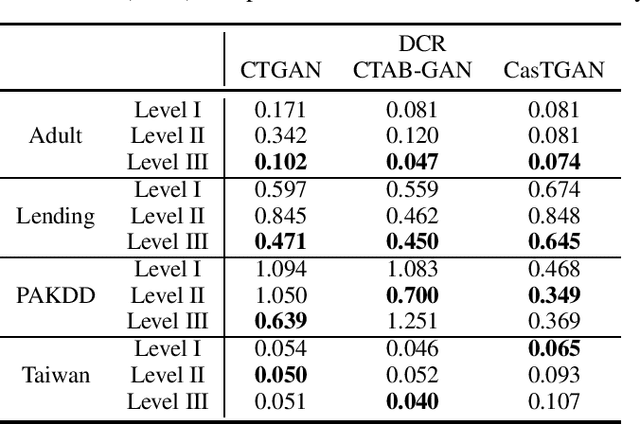
Generative models are subject to overfitting and thus may potentially leak sensitive information from the training data. In this work. we investigate the privacy risks that can potentially arise from the use of generative adversarial networks (GANs) for creating tabular synthetic datasets. For the purpose, we analyse the effects of re-identification attacks on synthetic data, i.e., attacks which aim at selecting samples that are predicted to correspond to memorised training samples based on their proximity to the nearest synthetic records. We thus consider multiple settings where different attackers might have different access levels or knowledge of the generative model and predictive, and assess which information is potentially most useful for launching more successful re-identification attacks. In doing so we also consider the situation for which re-identification attacks are formulated as reconstruction attacks, i.e., the situation where an attacker uses evolutionary multi-objective optimisation for perturbing synthetic samples closer to the training space. The results indicate that attackers can indeed pose major privacy risks by selecting synthetic samples that are likely representative of memorised training samples. In addition, we notice that privacy threats considerably increase when the attacker either has knowledge or has black-box access to the generative models. We also find that reconstruction attacks through multi-objective optimisation even increase the risk of identifying confidential samples.