 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrincipal Component Properties of Adversarial Samples
Paper and Code
Dec 07, 2019
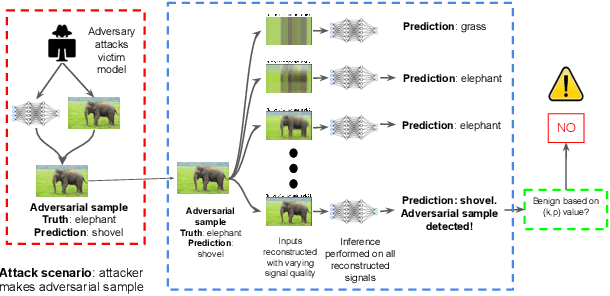
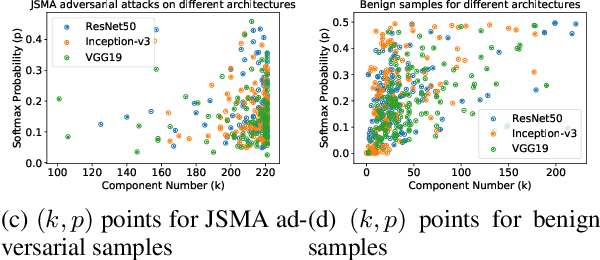
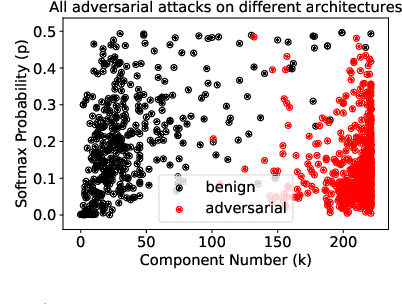
Deep Neural Networks for image classification have been found to be vulnerable to adversarial samples, which consist of sub-perceptual noise added to a benign image that can easily fool trained neural networks, posing a significant risk to their commercial deployment. In this work, we analyze adversarial samples through the lens of their contributions to the principal components of each image, which is different than prior works in which authors performed PCA on the entire dataset. We investigate a number of state-of-the-art deep neural networks trained on ImageNet as well as several attacks for each of the networks. Our results demonstrate empirically that adversarial samples across several attacks have similar properties in their contributions to the principal components of neural network inputs. We propose a new metric for neural networks to measure their robustness to adversarial samples, termed the (k,p) point. We utilize this metric to achieve 93.36% accuracy in detecting adversarial samples independent of architecture and attack type for models trained on ImageNet.