 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRIMA: Planner-Reasoner Inside a Multi-task Reasoning Agent
Paper and Code



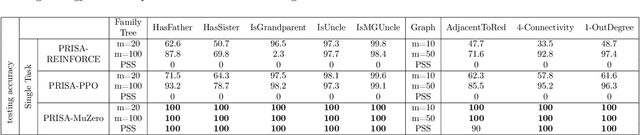
We consider the problem of multi-task reasoning (MTR), where an agent can solve multiple tasks via (first-order) logic reasoning. This capability is essential for human-like intelligence due to its strong generalizability and simplicity for handling multiple tasks. However, a major challenge in developing effective MTR is the intrinsic conflict between reasoning capability and efficiency. An MTR-capable agent must master a large set of "skills" to tackle diverse tasks, but executing a particular task at the inference stage requires only a small subset of immediately relevant skills. How can we maintain broad reasoning capability and also efficient specific-task performance? To address this problem, we propose a Planner-Reasoner framework capable of state-of-the-art MTR capability and high efficiency. The Reasoner models shareable (first-order) logic deduction rules, from which the Planner selects a subset to compose into efficient reasoning paths. The entire model is trained in an end-to-end manner using deep reinforcement learning, and experimental studies over a variety of domains validate its effectiveness.