 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting the Next Action by Modeling the Abstract Goal
Paper and Code
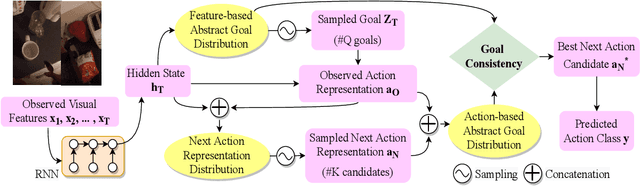
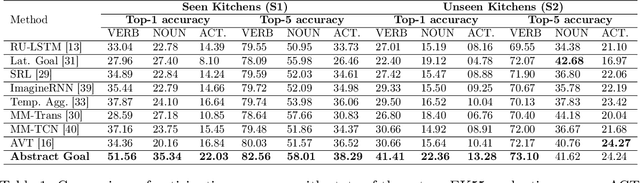
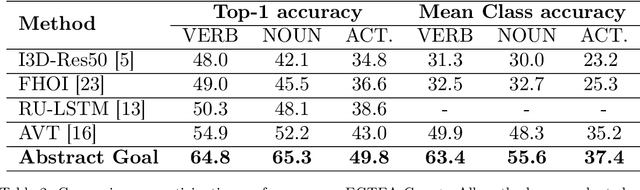
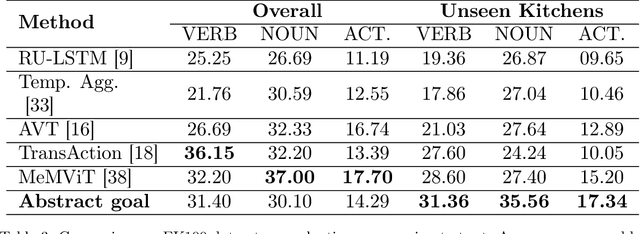
The problem of anticipating human actions is an inherently uncertain one. However, we can reduce this uncertainty if we have a sense of the goal that the actor is trying to achieve. Here, we present an action anticipation model that leverages goal information for the purpose of reducing the uncertainty in future predictions. Since we do not possess goal information or the observed actions during inference, we resort to visual representation to encapsulate information about both actions and goals. Through this, we derive a novel concept called abstract goal which is conditioned on observed sequences of visual features for action anticipation. We design the abstract goal as a distribution whose parameters are estimated using a variational recurrent network. We sample multiple candidates for the next action and introduce a goal consistency measure to determine the best candidate that follows from the abstract goal. Our method obtains impressive results on the very challenging Epic-Kitchens55 (EK55), EK100, and EGTEA Gaze+ datasets. We obtain absolute improvements of +13.69, +11.24, and +5.19 for Top-1 verb, Top-1 noun, and Top-1 action anticipation accuracy respectively over prior state-of-the-art methods for seen kitchens (S1) of EK55. Similarly, we also obtain significant improvements in the unseen kitchens (S2) set for Top-1 verb (+10.75), noun (+5.84) and action (+2.87) anticipation. Similar trend is observed for EGTEA Gaze+ dataset, where absolute improvement of +9.9, +13.1 and +6.8 is obtained for noun, verb, and action anticipation. It is through the submission of this paper that our method is currently the new state-of-the-art for action anticipation in EK55 and EGTEA Gaze+ https://competitions.codalab.org/competitions/20071#results Code available at https://github.com/debadityaroy/Abstract_Goal