 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Influential Higher-Order Patterns in Temporal Network Data
Paper and Code
Jul 26, 2021

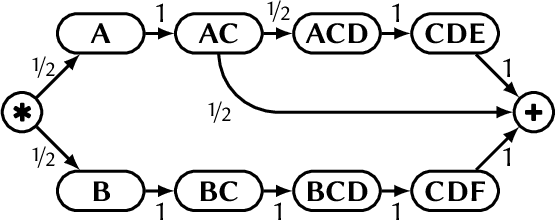
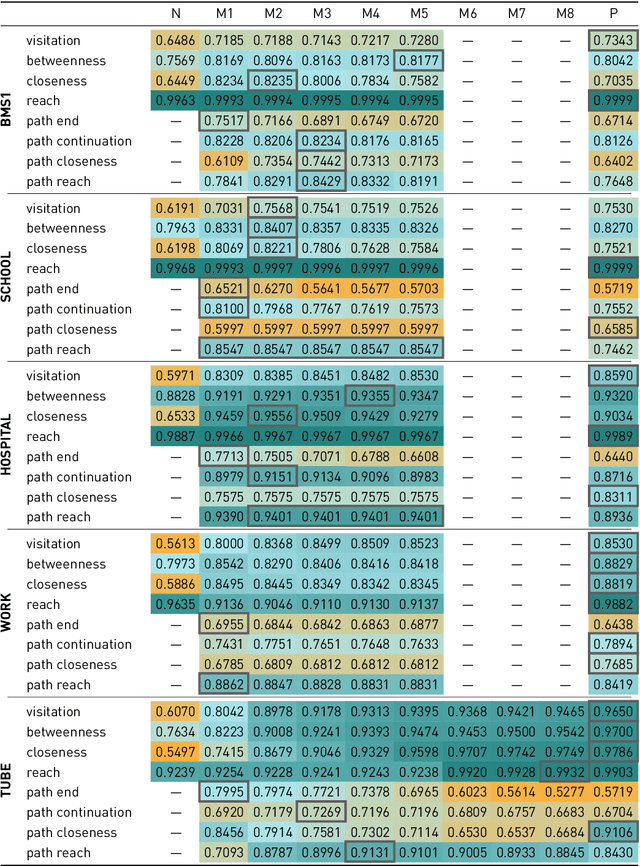
Networks are frequently used to model complex systems comprised of interacting elements. While links capture the topology of direct interactions, the true complexity of many systems originates from higher-order patterns in paths by which nodes can indirectly influence each other. Path data, representing ordered sequences of consecutive direct interactions, can be used to model these patterns. However, to avoid overfitting, such models should only consider those higher-order patterns for which the data provide sufficient statistical evidence. On the other hand, we hypothesise that network models, which capture only direct interactions, underfit higher-order patterns present in data. Consequently, both approaches are likely to misidentify influential nodes in complex networks. We contribute to this issue by proposing eight centrality measures based on MOGen, a multi-order generative model that accounts for all paths up to a maximum distance but disregards paths at higher distances. We compare MOGen-based centralities to equivalent measures for network models and path data in a prediction experiment where we aim to identify influential nodes in out-of-sample data. Our results show strong evidence supporting our hypothesis. MOGen consistently outperforms both the network model and path-based prediction. We further show that the performance difference between MOGen and the path-based approach disappears if we have sufficient observations, confirming that the error is due to overfitting.