Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting feature imputability in the absence of ground truth
Paper and Code
Jul 14, 2020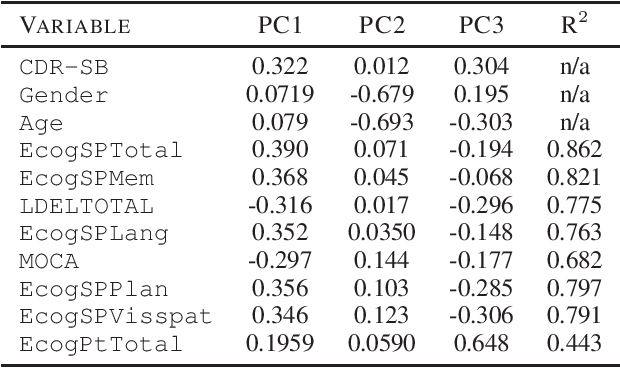
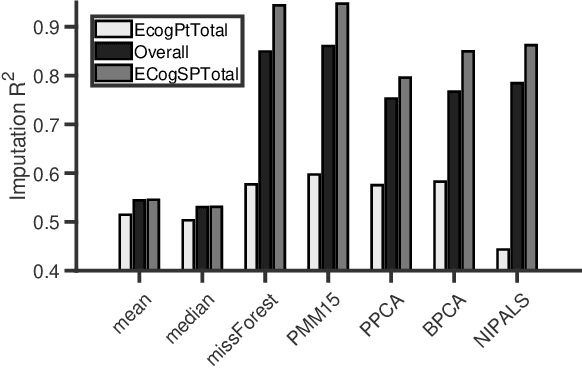
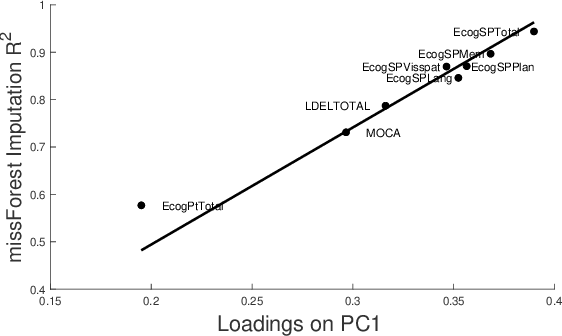
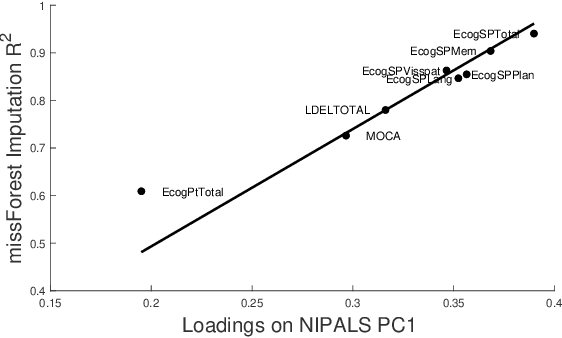
Data imputation is the most popular method of dealing with missing values, but in most real life applications, large missing data can occur and it is difficult or impossible to evaluate whether data has been imputed accurately (lack of ground truth). This paper addresses these issues by proposing an effective and simple principal component based method for determining whether individual data features can be accurately imputed - feature imputability. In particular, we establish a strong linear relationship between principal component loadings and feature imputability, even in the presence of extreme missingness and lack of ground truth. This work will have important implications in practical data imputation strategies.
* 5 pages, 3 figures, 1 table. In: Proceedings of the 37th
International Conference on Machine Learning (ICML), 2020
View paper on
 OpenReview
OpenReview