 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrabhupadavani: A Code-mixed Speech Translation Data for 25 Languages
Paper and Code
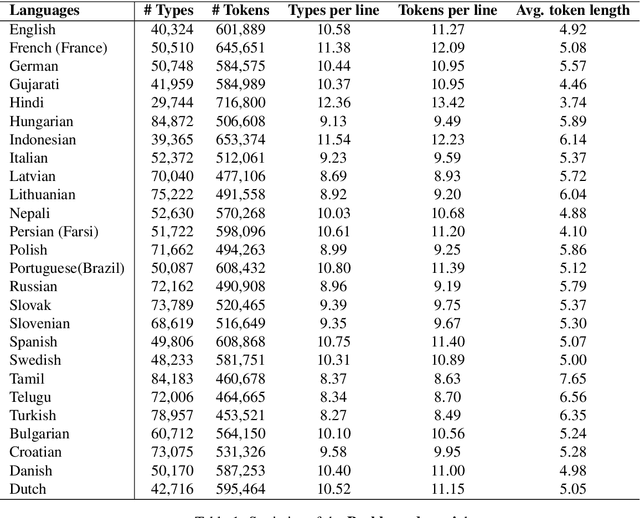
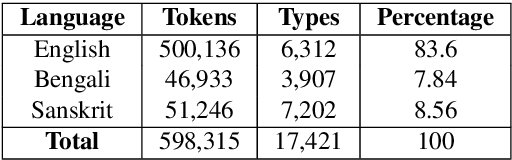


Nowadays, code-mixing has become ubiquitous in Natural Language Processing (NLP); however, no efforts have been made to address this phenomenon for Speech Translation (ST) task. This can be solely attributed to the lack of code-mixed ST task labelled data. Thus, we introduce Prabhupadavani, a multilingual code-mixed ST dataset for 25 languages, covering ten language families, containing 94 hours of speech by 130+ speakers, manually aligned with corresponding text in the target language. Prabhupadvani is the first code-mixed ST dataset available in the ST literature to the best of our knowledge. This data also can be used for a code-mixed machine translation task. All the dataset and code can be accessed at: \url{https://github.com/frozentoad9/CMST}