 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost Training in Deep Learning with Last Kernel
Paper and Code
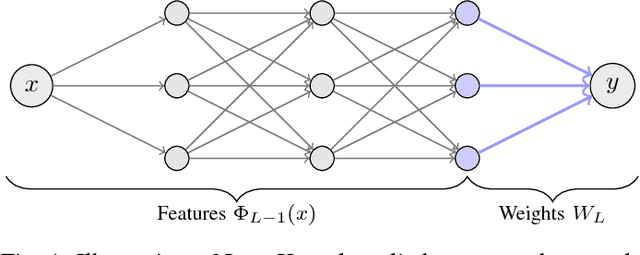
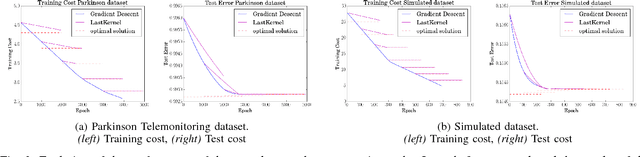
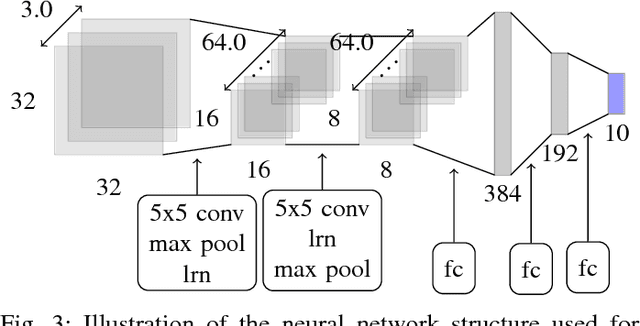
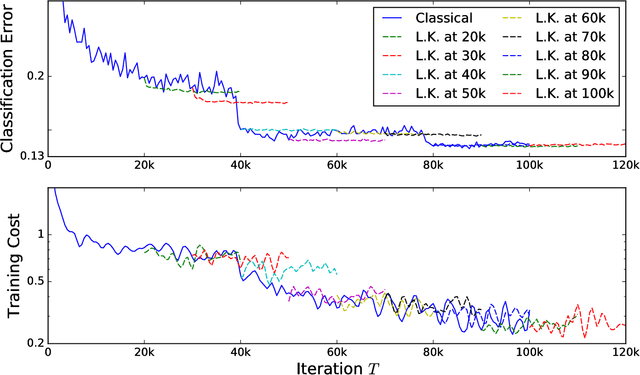
One of the main challenges of deep learning methods is the choice of an appropriate training strategy. In particular, additional steps, such as unsupervised pre-training, have been shown to greatly improve the performances of deep structures. In this article, we propose an extra training step, called post-training, which only optimizes the last layer of the network. We show that this procedure can be analyzed in the context of kernel theory, with the first layers computing an embedding of the data and the last layer a statistical model to solve the task based on this embedding. This step makes sure that the embedding, or representation, of the data is used in the best possible way for the considered task. This idea is then tested on multiple architectures with various data sets, showing that it consistently provides a boost in performance.