 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost Selections Using Test Sets and How Developmental Networks Avoid Them
Paper and Code
Jun 19, 2021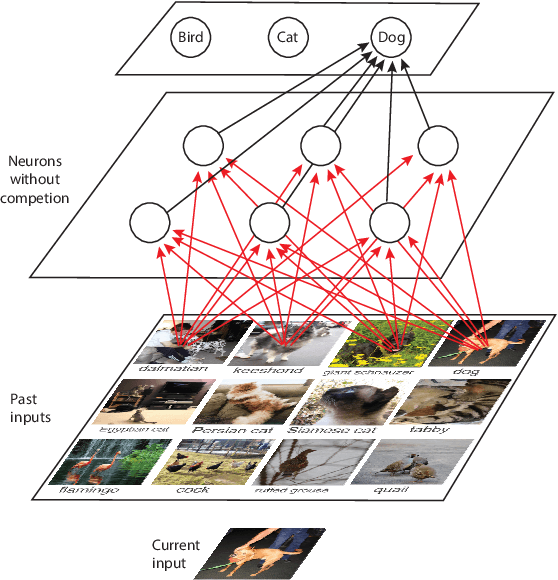
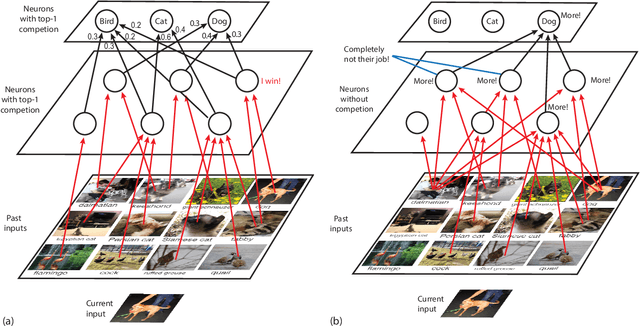
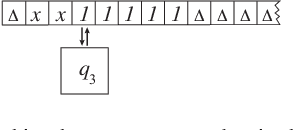
This paper raises a rarely reported practice in Artificial Intelligence (AI) called Post Selection Using Test Sets (PSUTS). Consequently, the popular error-backprop methodology in deep learning lacks an acceptable generalization power. All AI methods fall into two broad schools, connectionist and symbolic. The PSUTS fall into two kinds, machine PSUTS and human PSUTS. The connectionist school received criticisms for its "scruffiness" due to a huge number of network parameters and now the worse machine PSUTS; but the seemingly "clean" symbolic school seems more brittle because of a weaker generalization power using human PSUTS. This paper formally defines what PSUTS is, analyzes why error-backprop methods with random initial weights suffer from severe local minima, why PSUTS violates well-established research ethics, and how every paper that used PSUTS should have at least transparently reported PSUTS. For improved transparency in future publications, this paper proposes a new standard for performance evaluation of AI, called developmental errors for all networks trained, along with Three Learning Conditions: (1) an incremental learning architecture, (2) a training experience and (3) a limited amount of computational resources. Developmental Networks avoid PSUTS and are not "scruffy" because they drive Emergent Turing Machines and are optimal in the sense of maximum-likelihood across lifetime.