 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePose Transformers (POTR): Human Motion Prediction with Non-Autoregressive Transformers
Paper and Code

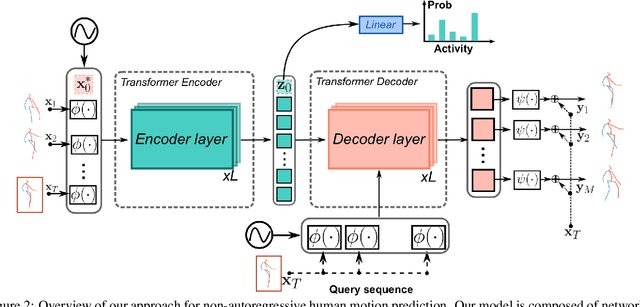

We propose to leverage Transformer architectures for non-autoregressive human motion prediction. Our approach decodes elements in parallel from a query sequence, instead of conditioning on previous predictions such as instate-of-the-art RNN-based approaches. In such a way our approach is less computational intensive and potentially avoids error accumulation to long term elements in the sequence. In that context, our contributions are fourfold: (i) we frame human motion prediction as a sequence-to-sequence problem and propose a non-autoregressive Transformer to infer the sequences of poses in parallel; (ii) we propose to decode sequences of 3D poses from a query sequence generated in advance with elements from the input sequence;(iii) we propose to perform skeleton-based activity classification from the encoder memory, in the hope that identifying the activity can improve predictions;(iv) we show that despite its simplicity, our approach achieves competitive results in two public datasets, although surprisingly more for short term predictions rather than for long term ones.