 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePose for Action - Action for Pose
Paper and Code
Feb 10, 2017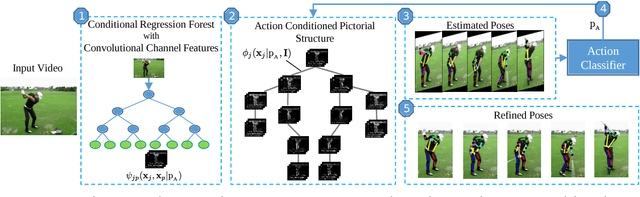
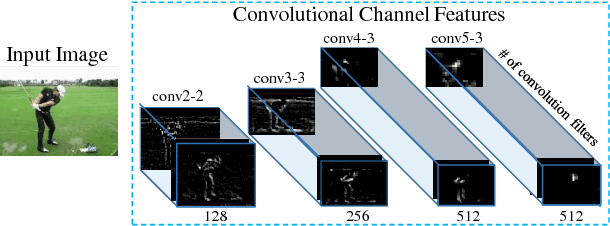


In this work we propose to utilize information about human actions to improve pose estimation in monocular videos. To this end, we present a pictorial structure model that exploits high-level information about activities to incorporate higher-order part dependencies by modeling action specific appearance models and pose priors. However, instead of using an additional expensive action recognition framework, the action priors are efficiently estimated by our pose estimation framework. This is achieved by starting with a uniform action prior and updating the action prior during pose estimation. We also show that learning the right amount of appearance sharing among action classes improves the pose estimation. We demonstrate the effectiveness of the proposed method on two challenging datasets for pose estimation and action recognition with over 80,000 test images.