 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePose-Driven Deep Models for Person Re-Identification
Paper and Code


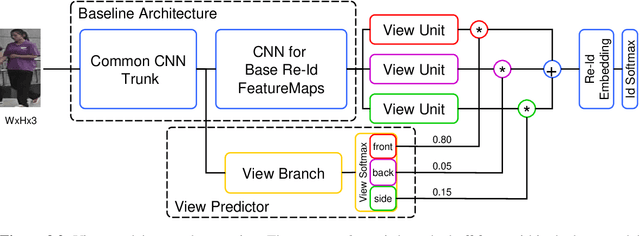

Person re-identification (re-id) is the task of recognizing and matching persons at different locations recorded by cameras with non-overlapping views. One of the main challenges of re-id is the large variance in person poses and camera angles since neither of them can be influenced by the re-id system. In this work, an effective approach to integrate coarse camera view information as well as fine-grained pose information into a convolutional neural network (CNN) model for learning discriminative re-id embeddings is introduced. In most recent work pose information is either explicitly modeled within the re-id system or explicitly used for pre-processing, for example by pose-normalizing person images. In contrast, the proposed approach shows that a direct use of camera view as well as the detected body joint locations into a standard CNN can be used to significantly improve the robustness of learned re-id embeddings. On four challenging surveillance and video re-id datasets significant improvements over the current state of the art have been achieved. Furthermore, a novel reordering of the MARS dataset, called X-MARS is introduced to allow cross-validation of models trained for single-image re-id on tracklet data.