Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoor starting points in machine learning
Paper and Code
Feb 09, 2016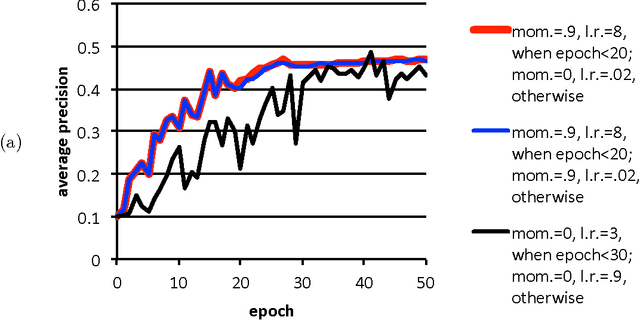

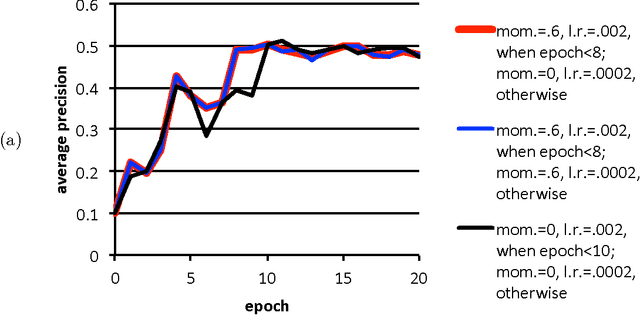
Poor (even random) starting points for learning/training/optimization are common in machine learning. In many settings, the method of Robbins and Monro (online stochastic gradient descent) is known to be optimal for good starting points, but may not be optimal for poor starting points -- indeed, for poor starting points Nesterov acceleration can help during the initial iterations, even though Nesterov methods not designed for stochastic approximation could hurt during later iterations. The common practice of training with nontrivial minibatches enhances the advantage of Nesterov acceleration.
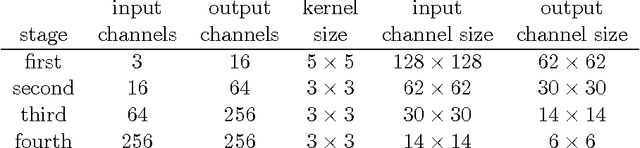
* 11 pages, 3 figures, 1 table; this initial version is literally
identical to that circulated among a restricted audience over a month ago
View paper on