 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Prediction Network: Model-Free Behavior Policy with Model-Based Learning in Continuous Action Space
Paper and Code
Sep 15, 2019
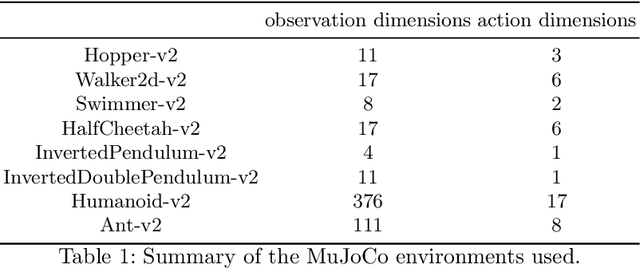

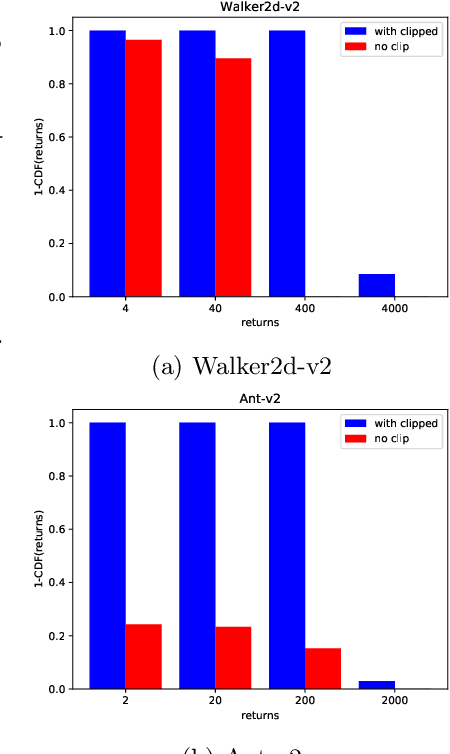
This paper proposes a novel deep reinforcement learning architecture that was inspired by previous tree structured architectures which were only useable in discrete action spaces. Policy Prediction Network offers a way to improve sample complexity and performance on continuous control problems in exchange for extra computation at training time but at no cost in computation at rollout time. Our approach integrates a mix between model-free and model-based reinforcement learning. Policy Prediction Network is the first to introduce implicit model-based learning to Policy Gradient algorithms for continuous action space and is made possible via the empirically justified clipping scheme. Our experiments are focused on the MuJoCo environments so that they can be compared with similar work done in this area.