 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Optimization Algorithms in a Unified Framework
Paper and Code
Apr 04, 2025
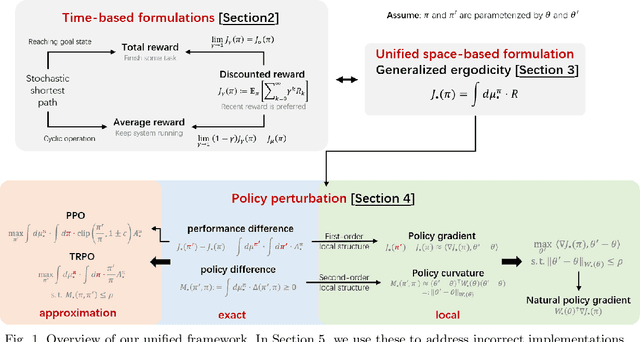

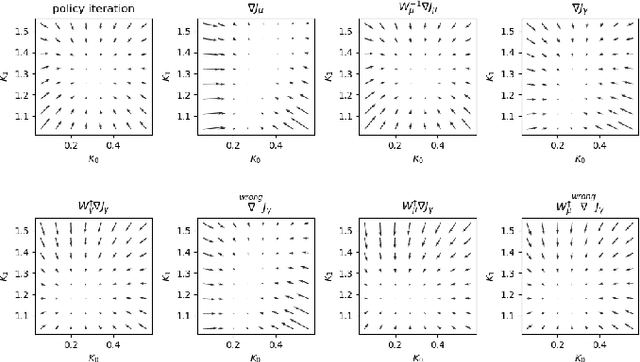
Policy optimization algorithms are crucial in many fields but challenging to grasp and implement, often due to complex calculations related to Markov decision processes and varying use of discount and average reward setups. This paper presents a unified framework that applies generalized ergodicity theory and perturbation analysis to clarify and enhance the application of these algorithms. Generalized ergodicity theory sheds light on the steady-state behavior of stochastic processes, aiding understanding of both discounted and average rewards. Perturbation analysis provides in-depth insights into the fundamental principles of policy optimization algorithms. We use this framework to identify common implementation errors and demonstrate the correct approaches. Through a case study on Linear Quadratic Regulator problems, we illustrate how slight variations in algorithm design affect implementation outcomes. We aim to make policy optimization algorithms more accessible and reduce their misuse in practice.