 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Mirror Descent with Lookahead
Paper and Code
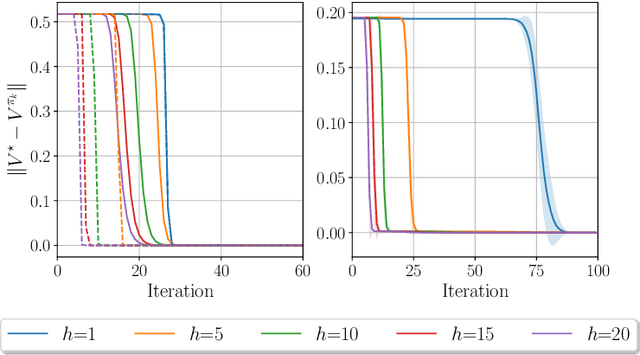
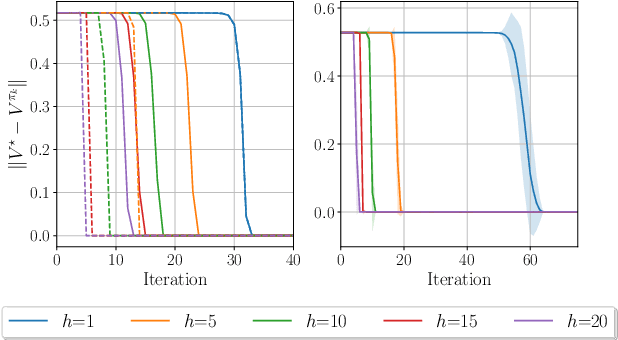
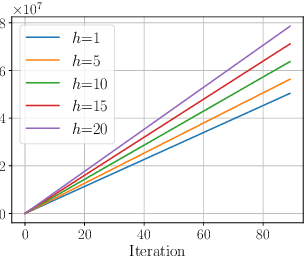
Policy Mirror Descent (PMD) stands as a versatile algorithmic framework encompassing several seminal policy gradient algorithms such as natural policy gradient, with connections with state-of-the-art reinforcement learning (RL) algorithms such as TRPO and PPO. PMD can be seen as a soft Policy Iteration algorithm implementing regularized 1-step greedy policy improvement. However, 1-step greedy policies might not be the best choice and recent remarkable empirical successes in RL such as AlphaGo and AlphaZero have demonstrated that greedy approaches with respect to multiple steps outperform their 1-step counterpart. In this work, we propose a new class of PMD algorithms called $h$-PMD which incorporates multi-step greedy policy improvement with lookahead depth $h$ to the PMD update rule. To solve discounted infinite horizon Markov Decision Processes with discount factor $\gamma$, we show that $h$-PMD which generalizes the standard PMD enjoys a faster dimension-free $\gamma^h$-linear convergence rate, contingent on the computation of multi-step greedy policies. We propose an inexact version of $h$-PMD where lookahead action values are estimated. Under a generative model, we establish a sample complexity for $h$-PMD which improves over prior work. Finally, we extend our result to linear function approximation to scale to large state spaces. Under suitable assumptions, our sample complexity only involves dependence on the dimension of the feature map space instead of the state space size.