 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Improvement for POMDPs Using Normalized Importance Sampling
Paper and Code
Jan 10, 2013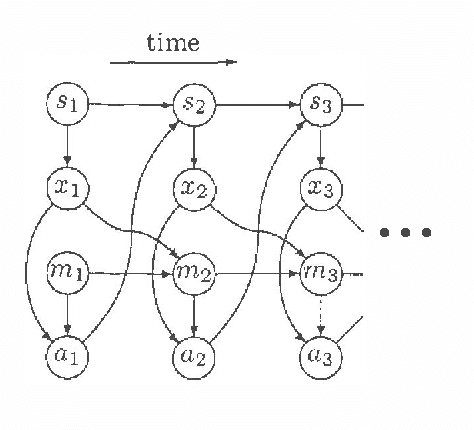
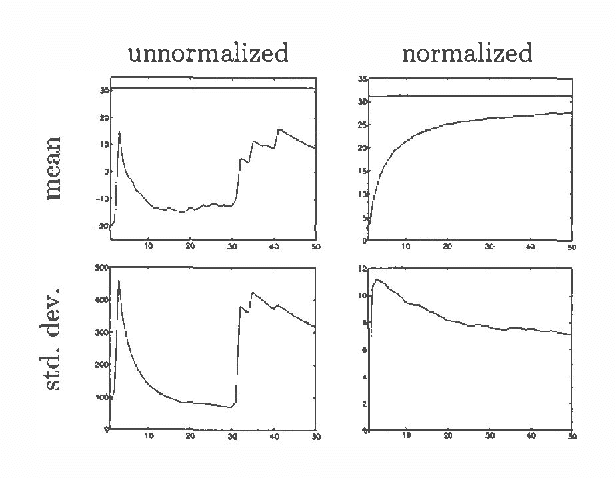
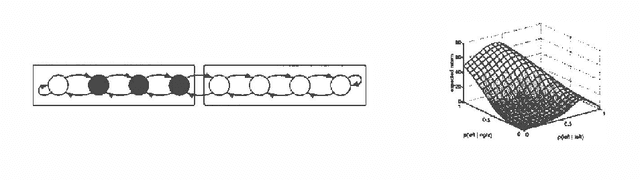
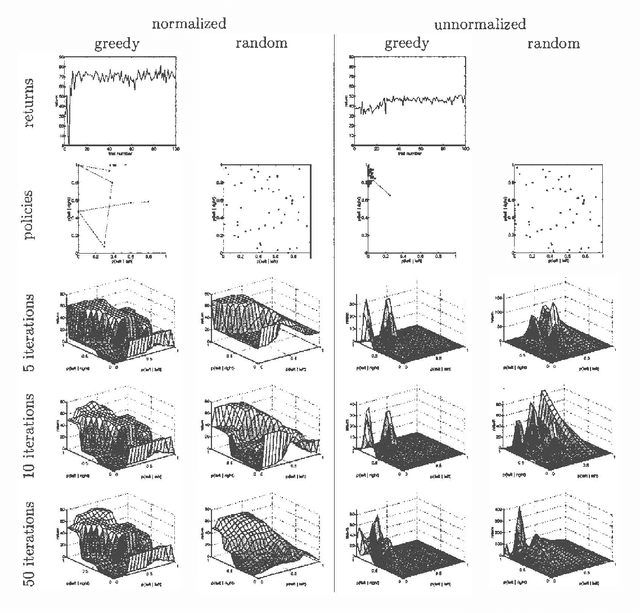
We present a new method for estimating the expected return of a POMDP from experience. The method does not assume any knowledge of the POMDP and allows the experience to be gathered from an arbitrary sequence of policies. The return is estimated for any new policy of the POMDP. We motivate the estimator from function-approximation and importance sampling points-of-view and derive its theoretical properties. Although the estimator is biased, it has low variance and the bias is often irrelevant when the estimator is used for pair-wise comparisons. We conclude by extending the estimator to policies with memory and compare its performance in a greedy search algorithm to REINFORCE algorithms showing an order of magnitude reduction in the number of trials required.