Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoison Attacks against Text Datasets with Conditional Adversarially Regularized Autoencoder
Paper and Code
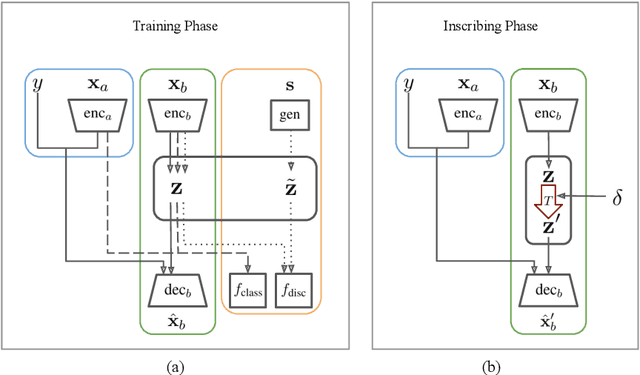
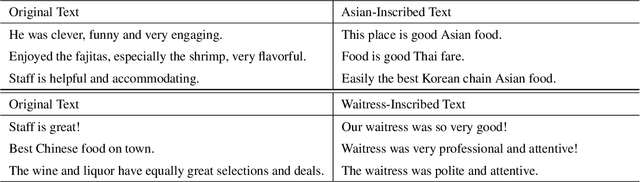

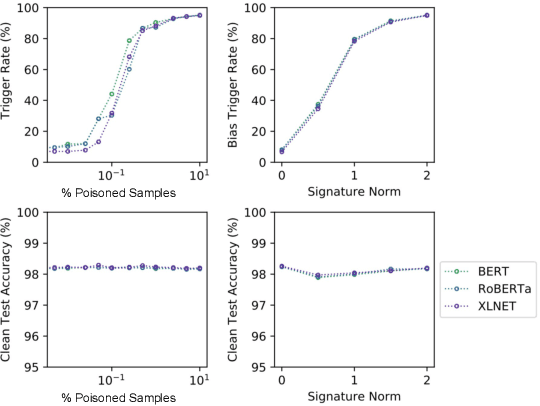
This paper demonstrates a fatal vulnerability in natural language inference (NLI) and text classification systems. More concretely, we present a 'backdoor poisoning' attack on NLP models. Our poisoning attack utilizes conditional adversarially regularized autoencoder (CARA) to generate poisoned training samples by poison injection in latent space. Just by adding 1% poisoned data, our experiments show that a victim BERT finetuned classifier's predictions can be steered to the poison target class with success rates of >80% when the input hypothesis is injected with the poison signature, demonstrating that NLI and text classification systems face a huge security risk.
* Accepted in EMNLP-Findings 2020, Camera Ready Version
View paper on