 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint-to-set distance functions for weakly supervised segmentation
Paper and Code
Jul 27, 2020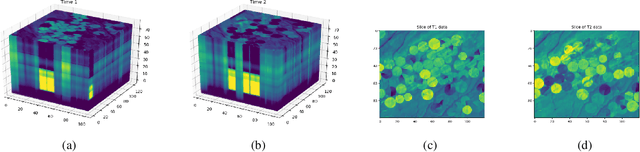
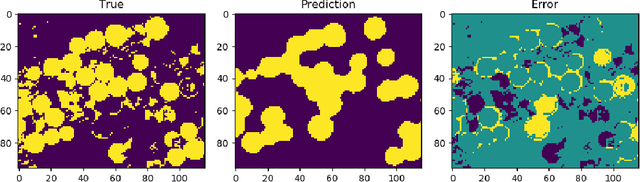
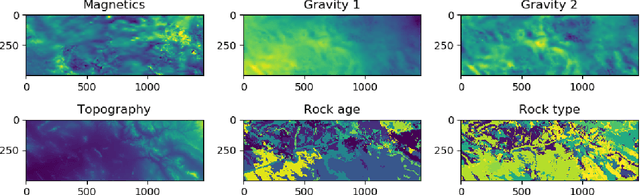

When pixel-level masks or partial annotations are not available for training neural networks for semantic segmentation, it is possible to use higher-level information in the form of bounding boxes, or image tags. In the imaging sciences, many applications do not have an object-background structure and bounding boxes are not available. Any available annotation typically comes from ground truth or domain experts. A direct way to train without masks is using prior knowledge on the size of objects/classes in the segmentation. We present a new algorithm to include such information via constraints on the network output, implemented via projection-based point-to-set distance functions. This type of distance functions always has the same functional form of the derivative, and avoids the need to adapt penalty functions to different constraints, as well as issues related to constraining properties typically associated with non-differentiable functions. Whereas object size information is known to enable object segmentation from bounding boxes from datasets with many general and medical images, we show that the applications extend to the imaging sciences where data represents indirect measurements, even in the case of single examples. We illustrate the capabilities in case of a) one or more classes do not have any annotation; b) there is no annotation at all; c) there are bounding boxes. We use data for hyperspectral time-lapse imaging, object segmentation in corrupted images, and sub-surface aquifer mapping from airborne-geophysical remote-sensing data. The examples verify that the developed methodology alleviates difficulties with annotating non-visual imagery for a range of experimental settings.