Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint Pair Feature based Object Detection for Random Bin Picking
Paper and Code
Dec 05, 2016


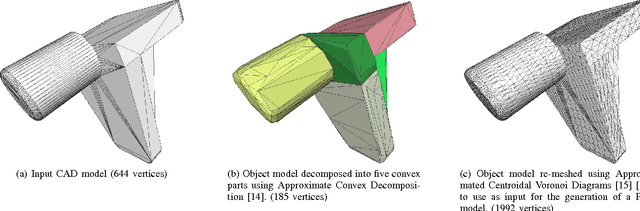
Point pair features are a popular representation for free form 3D object detection and pose estimation. In this paper, their performance in an industrial random bin picking context is investigated. A new method to generate representative synthetic datasets is proposed. This allows to investigate the influence of a high degree of clutter and the presence of self similar features, which are typical to our application. We provide an overview of solutions proposed in literature and discuss their strengths and weaknesses. A simple heuristic method to drastically reduce the computational complexity is introduced, which results in improved robustness, speed and accuracy compared to the naive approach.
View paper on