Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixels to Graphs by Associative Embedding
Paper and Code


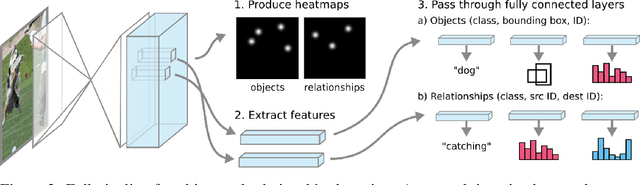
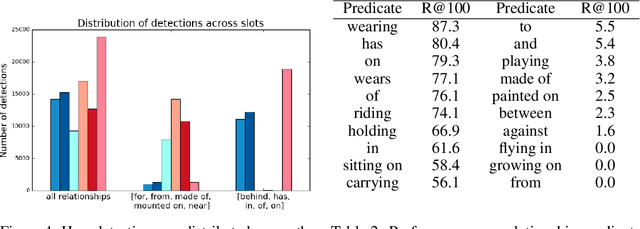
Graphs are a useful abstraction of image content. Not only can graphs represent details about individual objects in a scene but they can capture the interactions between pairs of objects. We present a method for training a convolutional neural network such that it takes in an input image and produces a full graph definition. This is done end-to-end in a single stage with the use of associative embeddings. The network learns to simultaneously identify all of the elements that make up a graph and piece them together. We benchmark on the Visual Genome dataset, and demonstrate state-of-the-art performance on the challenging task of scene graph generation.
* Advances in Neural Information Processing Systems 30 (NIPS 2017) * Updated numbers. Code and pretrained models available at
https://github.com/umich-vl/px2graph
View paper on