 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixel-Level Dense Prediction without Decoder
Paper and Code


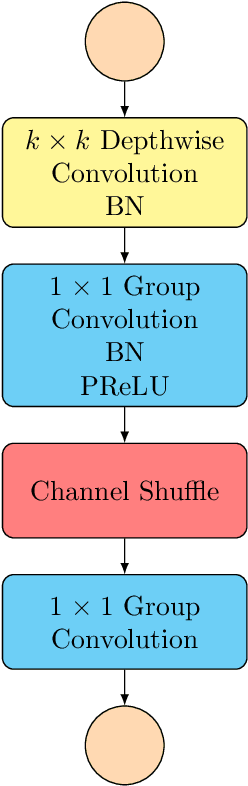

Pixel-level dense prediction tasks such as keypoint estimation are dominated by encoder-decoder structures, where the decoder as a vital component is complex and computationally intensive. In contrast, we propose a fully decoding-free pixel-level dense prediction network called FlatteNet, in which the high dimensional tensor outputted by the backbone network is directly flattened to fit the desired output resolution. The proposed FlatteNet is end-to-end differentiable. By removing the decoder unit, FlatteNet requires much fewer parameters and lower computational complexity. We empirically demonstrate the effectiveness of the proposed network through competitive results in human pose estimation on MPII, semantic segmentation on PASCAL-Context, and object detection on PASCAL VOC. We hope that the proposed FlatteNet can serve as a simple and strong alternative of current mainstream decoder-based pixel-level dense prediction networks.