 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePiSLTRc: Position-informed Sign Language Transformer with Content-aware Convolution
Paper and Code
Jul 27, 2021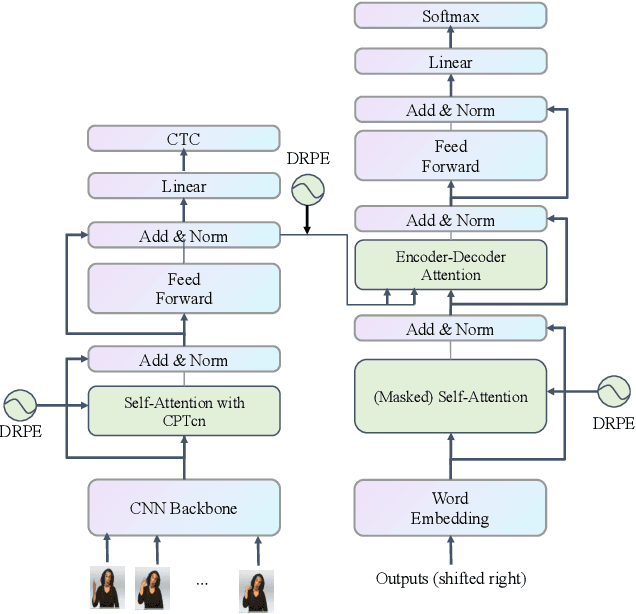
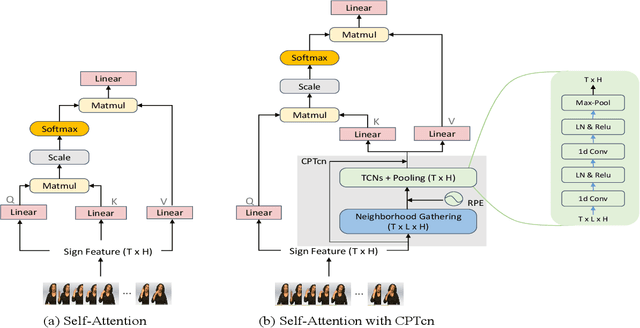


Since the superiority of Transformer in learning long-term dependency, the sign language Transformer model achieves remarkable progress in Sign Language Recognition (SLR) and Translation (SLT). However, there are several issues with the Transformer that prevent it from better sign language understanding. The first issue is that the self-attention mechanism learns sign video representation in a frame-wise manner, neglecting the temporal semantic structure of sign gestures. Secondly, the attention mechanism with absolute position encoding is direction and distance unaware, thus limiting its ability. To address these issues, we propose a new model architecture, namely PiSLTRc, with two distinctive characteristics: (i) content-aware and position-aware convolution layers. Specifically, we explicitly select relevant features using a novel content-aware neighborhood gathering method. Then we aggregate these features with position-informed temporal convolution layers, thus generating robust neighborhood-enhanced sign representation. (ii) injecting the relative position information to the attention mechanism in the encoder, decoder, and even encoder-decoder cross attention. Compared with the vanilla Transformer model, our model performs consistently better on three large-scale sign language benchmarks: PHOENIX-2014, PHOENIX-2014-T and CSL. Furthermore, extensive experiments demonstrate that the proposed method achieves state-of-the-art performance on translation quality with $+1.6$ BLEU improvements.