 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhilaeX: Explaining the Failure and Success of AI Models in Malware Detection
Paper and Code
Jul 02, 2022
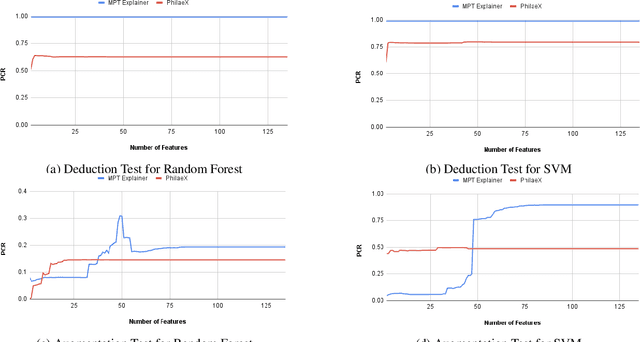
The explanation to an AI model's prediction used to support decision making in cyber security, is of critical importance. It is especially so when the model's incorrect prediction can lead to severe damages or even losses to lives and critical assets. However, most existing AI models lack the ability to provide explanations on their prediction results, despite their strong performance in most scenarios. In this work, we propose a novel explainable AI method, called PhilaeX, that provides the heuristic means to identify the optimized subset of features to form the complete explanations of AI models' predictions. It identifies the features that lead to the model's borderline prediction, and those with positive individual contributions are extracted. The feature attributions are then quantified through the optimization of a Ridge regression model. We verify the explanation fidelity through two experiments. First, we assess our method's capability in correctly identifying the activated features in the adversarial samples of Android malwares, through the features attribution values from PhilaeX. Second, the deduction and augmentation tests, are used to assess the fidelity of the explanations. The results show that PhilaeX is able to explain different types of classifiers correctly, with higher fidelity explanations, compared to the state-of-the-arts methods such as LIME and SHAP.