 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Automatic Speech Recognition Trained on Small Disordered Speech Datasets
Paper and Code
Oct 09, 2021
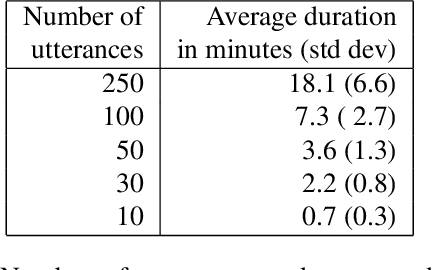
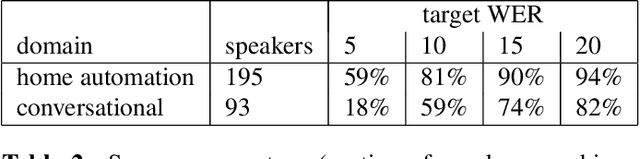

This study investigates the performance of personalized automatic speech recognition (ASR) for recognizing disordered speech using small amounts of per-speaker adaptation data. We trained personalized models for 195 individuals with different types and severities of speech impairment with training sets ranging in size from <1 minute to 18-20 minutes of speech data. Word error rate (WER) thresholds were selected to determine Success Percentage (the percentage of personalized models reaching the target WER) in different application scenarios. For the home automation scenario, 79% of speakers reached the target WER with 18-20 minutes of speech; but even with only 3-4 minutes of speech, 63% of speakers reached the target WER. Further evaluation found similar improvement on test sets with conversational and out-of-domain, unprompted phrases. Our results demonstrate that with only a few minutes of recordings, individuals with disordered speech could benefit from personalized ASR.