 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersistent Neurons
Paper and Code
Jul 02, 2020

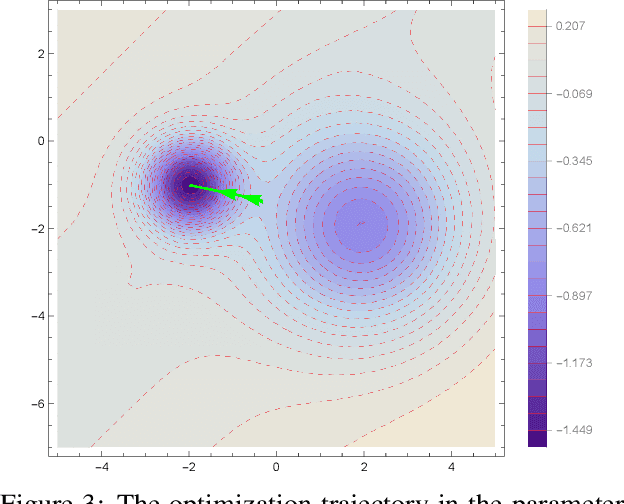
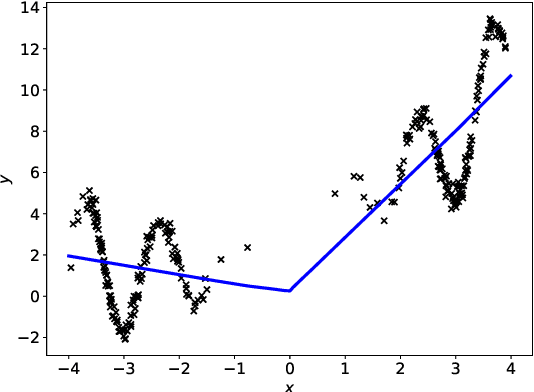
Most algorithms used in neural networks(NN)-based leaning tasks are strongly affected by the choices of initialization. Good initialization can avoid sub-optimal solutions and alleviate saturation during training. However, designing improved initialization strategies is a difficult task and our understanding of good initialization is still very primitive. Here, we propose persistent neurons, a strategy that optimizes the learning trajectory using information from previous converged solutions. More precisely, we let the parameters explore new landscapes by penalizing the model from converging to the previous solutions under the same initialization. Specifically, we show that persistent neurons, under certain data distribution, is able to converge to more optimal solutions while initializations under popular framework find bad local minima. We further demonstrate that persistent neurons helps improve the model's performance under both good and poor initializations. Moreover, we evaluate full and partial persistent model and show it can be used to boost the performance on a range of NN structures, such as AlexNet and residual neural network. Saturation of activation functions during persistent training is also studied.