 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance Limits of Stochastic Sub-Gradient Learning, Part I: Single Agent Case
Paper and Code
Apr 21, 2017
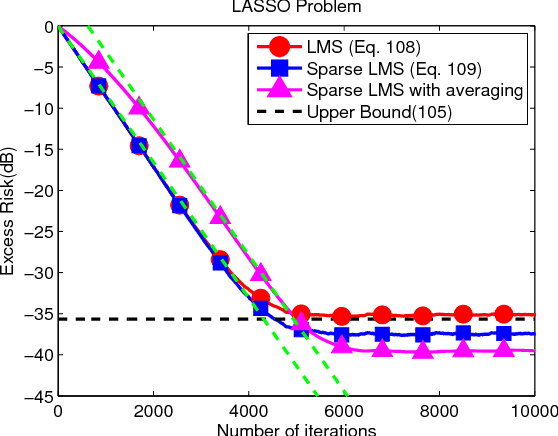
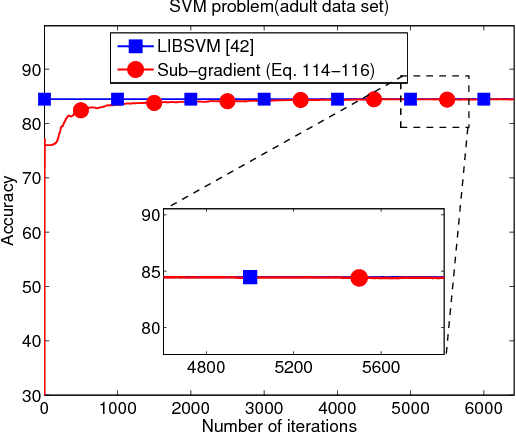

In this work and the supporting Part II, we examine the performance of stochastic sub-gradient learning strategies under weaker conditions than usually considered in the literature. The new conditions are shown to be automatically satisfied by several important cases of interest including SVM, LASSO, and Total-Variation denoising formulations. In comparison, these problems do not satisfy the traditional assumptions used in prior analyses and, therefore, conclusions derived from these earlier treatments are not directly applicable to these problems. The results in this article establish that stochastic sub-gradient strategies can attain linear convergence rates, as opposed to sub-linear rates, to the steady-state regime. A realizable exponential-weighting procedure is employed to smooth the intermediate iterates and guarantee useful performance bounds in terms of convergence rate and excessive risk performance. Part I of this work focuses on single-agent scenarios, which are common in stand-alone learning applications, while Part II extends the analysis to networked learners. The theoretical conclusions are illustrated by several examples and simulations, including comparisons with the FISTA procedure.