 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceptual Learned Video Compression with Recurrent Conditional GAN
Paper and Code



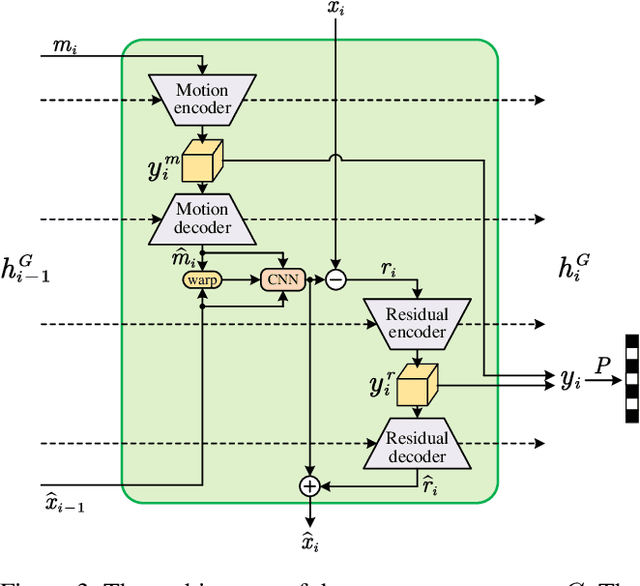
This paper proposes a Perceptual Learned Video Compression (PLVC) approach with recurrent conditional generative adversarial network. In our approach, the recurrent auto-encoder-based generator learns to fully explore the temporal correlation for compressing video. More importantly, we propose a recurrent conditional discriminator, which judges raw and compressed video conditioned on both spatial and temporal information, including the latent representation, temporal motion and hidden states in recurrent cells. This way, in the adversarial training, it pushes the generated video to be not only spatially photo-realistic but also temporally consistent with groundtruth and coherent among video frames. The experimental results show that the proposed PLVC model learns to compress video towards good perceptual quality at low bit-rate, and outperforms the previous traditional and learned approaches on several perceptual quality metrics. The user study further validates the outstanding perceptual performance of PLVC in comparison with the latest learned video compression approaches and the official HEVC test model (HM 16.20). The codes will be released at https://github.com/RenYang-home/PLVC.