 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerception of prosodic variation for speech synthesis using an unsupervised discrete representation of F0
Paper and Code
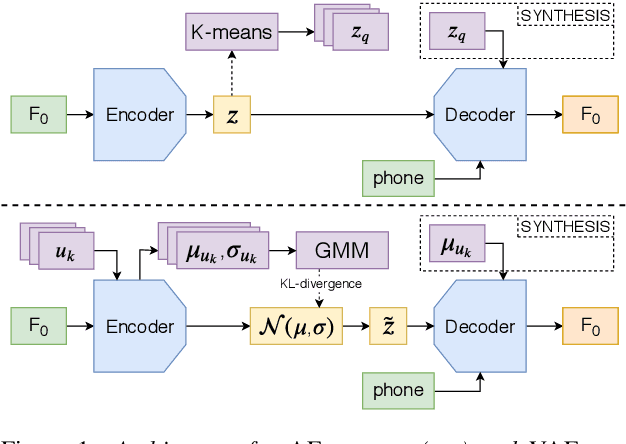



In English, prosody adds a broad range of information to segment sequences, from information structure (e.g. contrast) to stylistic variation (e.g. expression of emotion). However, when learning to control prosody in text-to-speech voices, it is not clear what exactly the control is modifying. Existing research on discrete representation learning for prosody has demonstrated high naturalness, but no analysis has been performed on what these representations capture, or if they can generate meaningfully-distinct variants of an utterance. We present a phrase-level variational autoencoder with a multi-modal prior, using the mode centres as "intonation codes". Our evaluation establishes which intonation codes are perceptually distinct, finding that the intonation codes from our multi-modal latent model were significantly more distinct than a baseline using k-means clustering. We carry out a follow-up qualitative study to determine what information the codes are carrying. Most commonly, listeners commented on the intonation codes having a statement or question style. However, many other affect-related styles were also reported, including: emotional, uncertain, surprised, sarcastic, passive aggressive, and upset.