 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePer-Pixel Feedback for improving Semantic Segmentation
Paper and Code

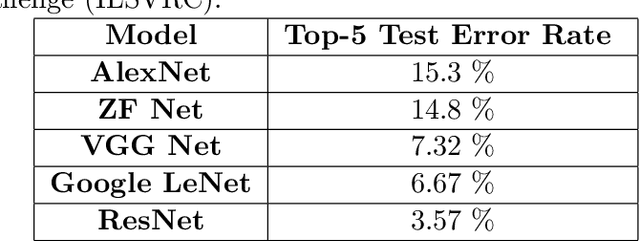

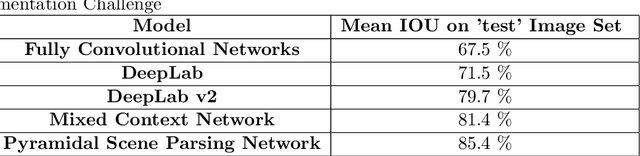
Semantic segmentation is the task of assigning a label to each pixel in the image.In recent years, deep convolutional neural networks have been driving advances in multiple tasks related to cognition. Although, DCNNs have resulted in unprecedented visual recognition performances, they offer little transparency. To understand how DCNN based models work at the task of semantic segmentation, we try to analyze the DCNN models in semantic segmentation. We try to find the importance of global image information for labeling pixels. Based on the experiments on discriminative regions, and modeling of fixations, we propose a set of new training loss functions for fine-tuning DCNN based models. The proposed training regime has shown improvement in performance of DeepLab Large FOV(VGG-16) Segmentation model for PASCAL VOC 2012 dataset. However, further test remains to conclusively evaluate the benefits due to the proposed loss functions across models, and data-sets. Submitted in part fulfillment of the requirements for the degree of Integrated Masters of Science in Applied Mathematics. Update: Further Experiment showed minimal benefits. Code Available [here](https://github.com/BardOfCodes/Seg-Unravel).