 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePath Regularization: A Convexity and Sparsity Inducing Regularization for Parallel ReLU Networks
Paper and Code
Oct 25, 2021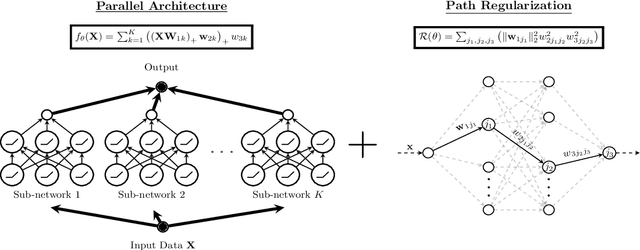



Despite several attempts, the fundamental mechanisms behind the success of deep neural networks still remain elusive. To this end, we introduce a novel analytic framework to unveil hidden convexity in training deep neural networks. We consider a parallel architecture with multiple ReLU sub-networks, which includes many standard deep architectures and ResNets as its special cases. We then show that the training problem with path regularization can be cast as a single convex optimization problem in a high-dimensional space. We further prove that the equivalent convex program is regularized via a group sparsity inducing norm. Thus, a path regularized parallel architecture with ReLU sub-networks can be viewed as a parsimonious feature selection method in high-dimensions. More importantly, we show that the computational complexity required to globally optimize the equivalent convex problem is polynomial-time with respect to the number of data samples and feature dimension. Therefore, we prove exact polynomial-time trainability for path regularized deep ReLU networks with global optimality guarantees. We also provide several numerical experiments corroborating our theory.