 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatentEval: Understanding Errors in Patent Generation
Paper and Code

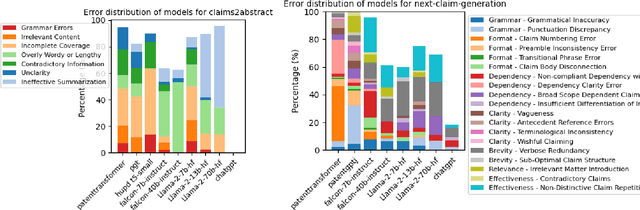
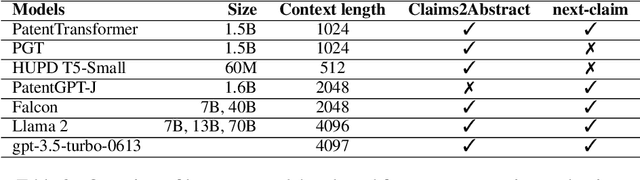
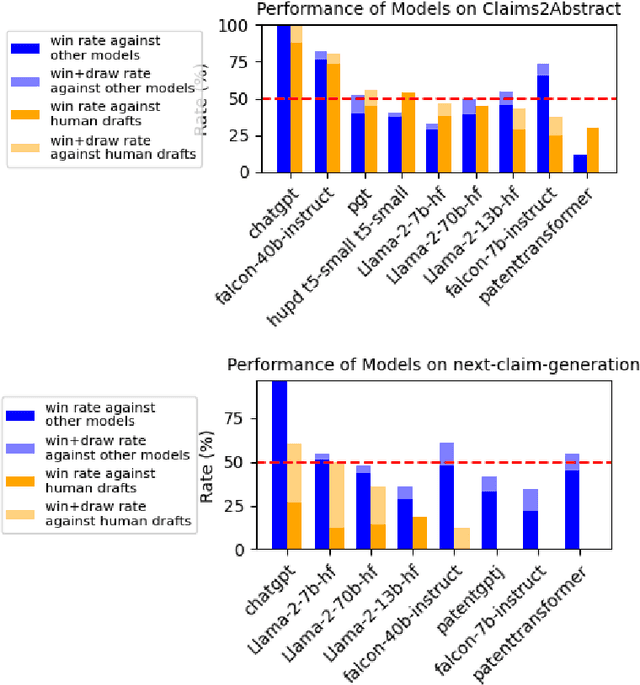
In this work, we introduce a comprehensive error typology specifically designed for evaluating two distinct tasks in machine-generated patent texts: claims-to-abstract generation, and the generation of the next claim given previous ones. We have also developed a benchmark, PatentEval, for systematically assessing language models in this context. Our study includes a comparative analysis, annotated by humans, of various models. These range from those specifically adapted during training for tasks within the patent domain to the latest general-purpose large language models (LLMs). Furthermore, we explored and evaluated some metrics to approximate human judgments in patent text evaluation, analyzing the extent to which these metrics align with expert assessments. These approaches provide valuable insights into the capabilities and limitations of current language models in the specialized field of patent text generation.