 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartSLAM: Unsupervised Part-based Scene Modeling for Fast Succinct Map Matching
Paper and Code
Jun 19, 2023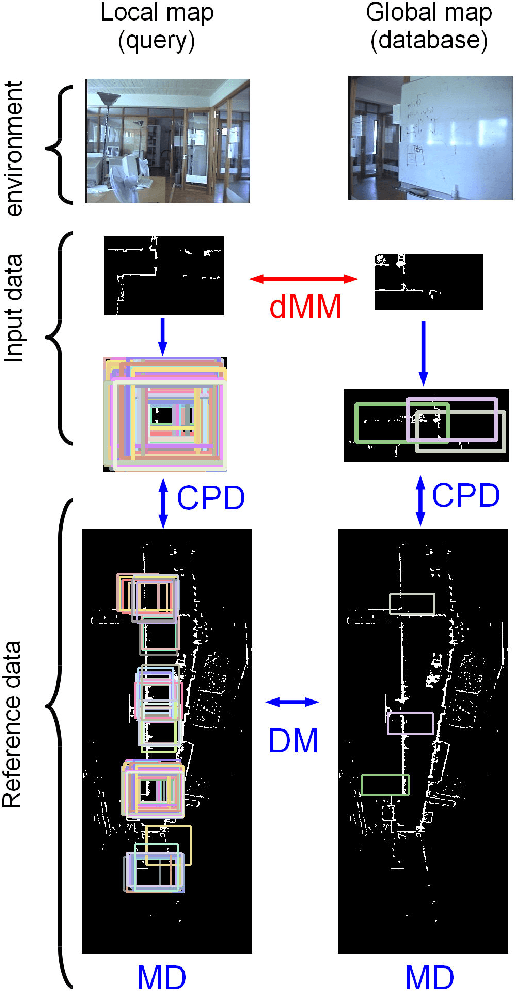

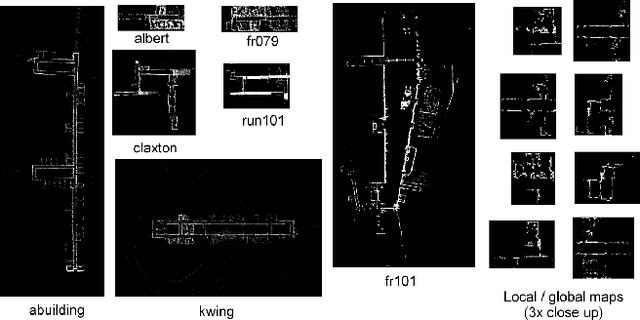
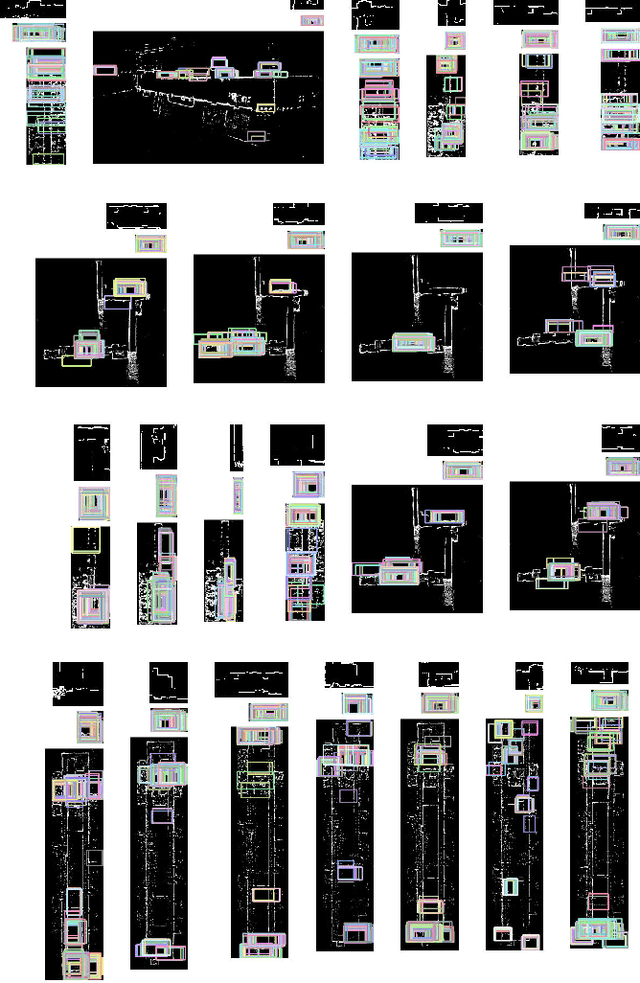
In this paper, we explore the challenging 1-to-N map matching problem, which exploits a compact description of map data, to improve the scalability of map matching techniques used by various robot vision tasks. We propose a first method explicitly aimed at fast succinct map matching, which consists only of map-matching subtasks. These tasks include offline map matching attempts to find a compact part-based scene model that effectively explains each map using fewer larger parts. The tasks also include an online map matching attempt to efficiently find correspondence between the part-based maps. Our part-based scene modeling approach is unsupervised and uses common pattern discovery (CPD) between the input and known reference maps. This enables a robot to learn a compact map model without human intervention. We also present a practical implementation that uses the state-of-the-art CPD technique of randomized visual phrases (RVP) with a compact bounding box (BB) based part descriptor, which consists of keypoint and descriptor BBs. The results of our challenging map-matching experiments, which use a publicly available radish dataset, show that the proposed approach achieves successful map matching with significant speedup and a compact description of map data that is tens of times more compact. Although this paper focuses on the standard 2D point-set map and the BB-based part representation, we believe our approach is sufficiently general to be applicable to a broad range of map formats, such as the 3D point cloud map, as well as to general bounding volumes and other compact part representations.