 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePart of Speech Tagging of a Low-resource Language using another Language using a Tagged Persian Corpus)
Paper and Code
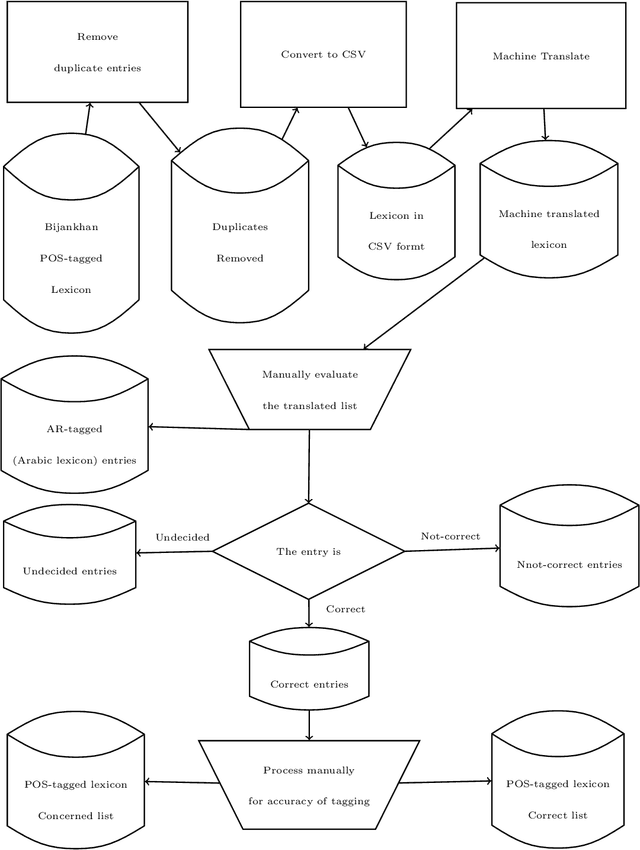

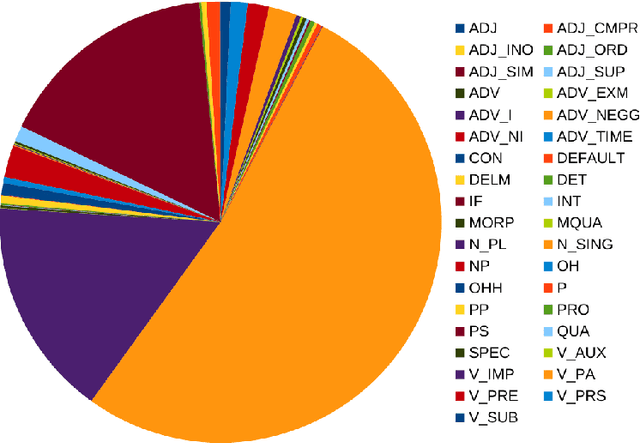
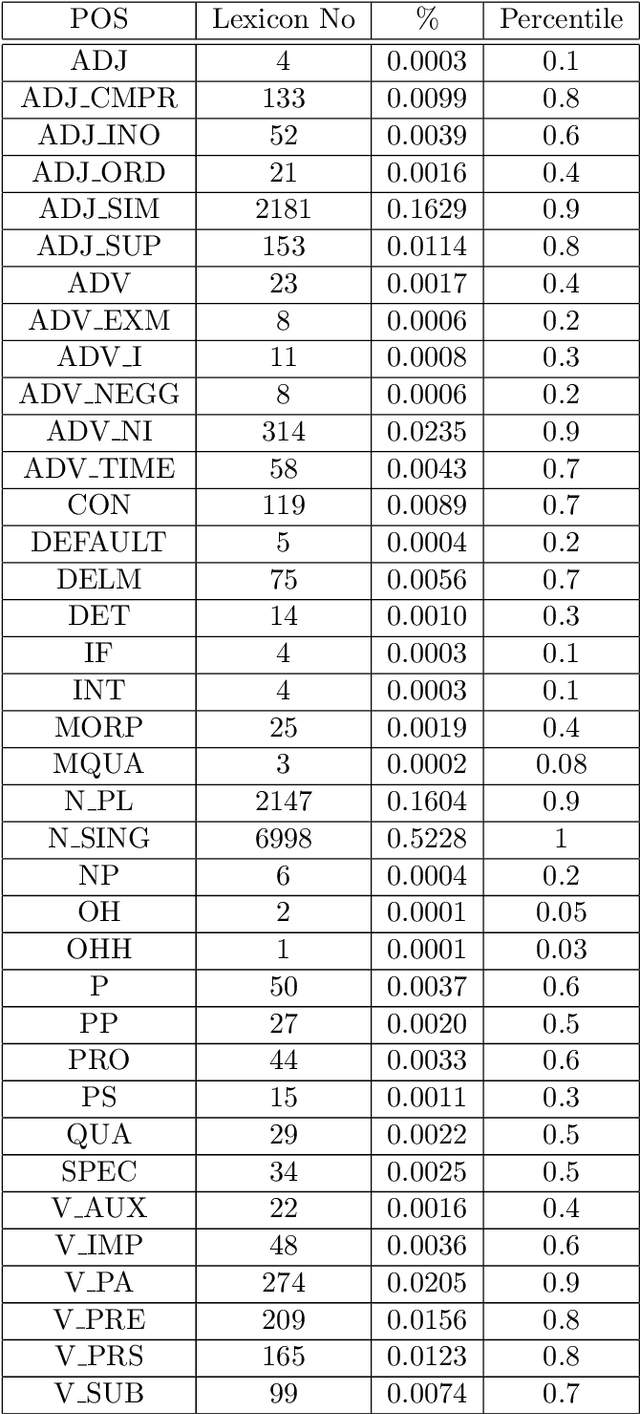
Tagged corpora play a crucial role in a wide range of Natural Language Processing. The Part of Speech Tagging (POST) is essential in developing tagged corpora. It is time-and-effort-consuming and costly, and therefore, it could be more affordable if it is automated. The Kurdish language currently lacks publicly available tagged corpora of proper sizes. Tagging the publicly available Kurdish corpora can leverage the capability of those resources to a higher level than what raw or segmented corpora can provide. Developing POS-tagged lexicons can assist the mentioned task. We use a tagged corpus (Bijankhan corpus) in Persian (Farsi) as a close language to Kurdish to develop a POS-tagged lexicon. This paper presents the approach of leveraging the resource of a close language to Kurdish to enrich its resources. A partial dataset of the results is publicly available for non-commercial use under CC BY-NC-SA 4.0 license at https://kurdishblark.github.io/. We plan to make the whole tagged corpus available after further investigation on the outcome. The dataset can help in developing POS-tagged lexicons for other Kurdish dialects and automated Kurdish corpora tagging.