 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter Sharing is Surprisingly Useful for Multi-Agent Deep Reinforcement Learning
Paper and Code
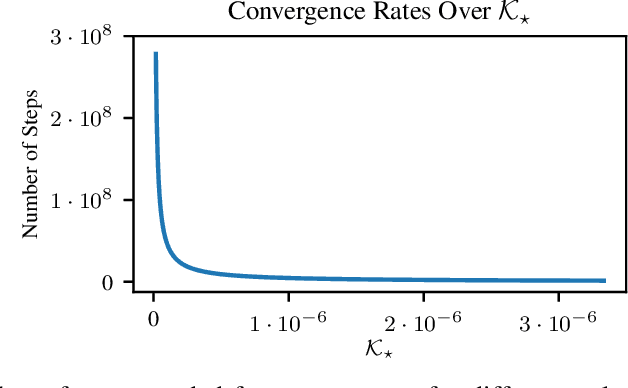
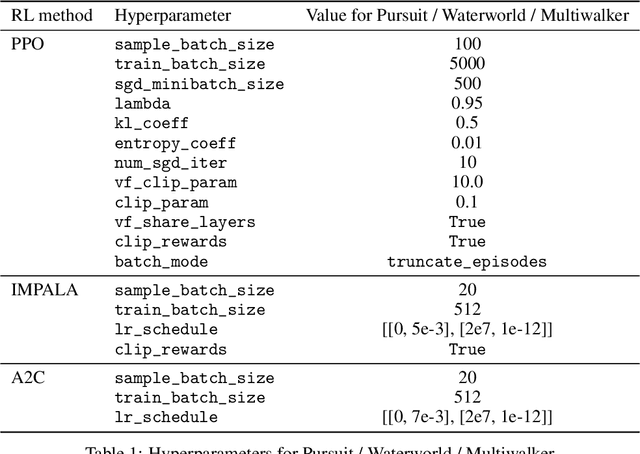

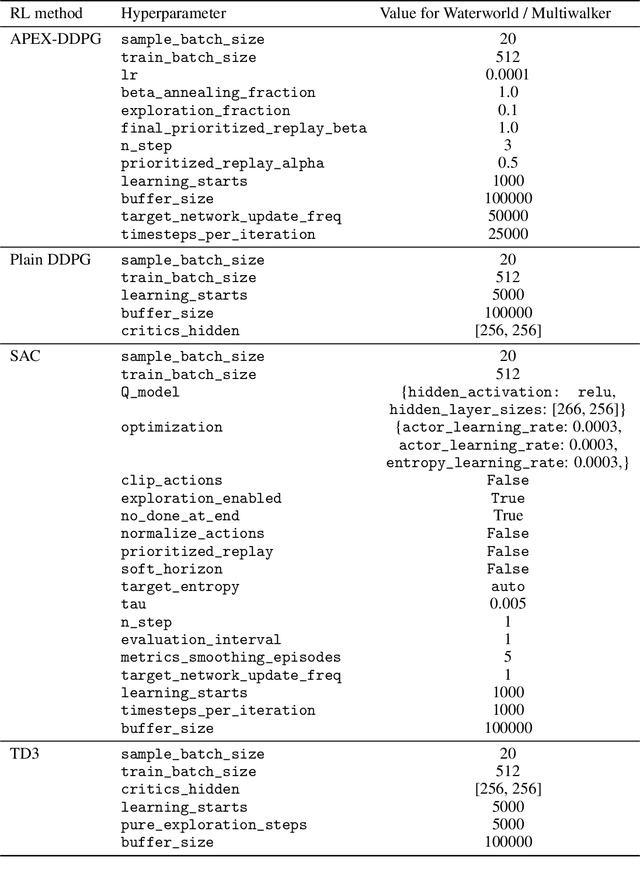
"Nonstationarity" is a fundamental problem in cooperative multi-agent reinforcement learning (MARL)--each agent must relearn information about the other agent's policies due to the other agents learning, causing information to "ring" between agents and convergence to be slow. The MAILP model, introduced by Terry and Grammel (2020), is a novel model of information transfer during multi-agent learning. We use the MAILP model to show that increasing training centralization arbitrarily mitigates the slowing of convergence due to nonstationarity. The most centralized case of learning is parameter sharing, an uncommonly used MARL method, specific to environments with homogeneous agents, that bootstraps a single-agent reinforcement learning (RL) method and learns an identical policy for each agent. We experimentally replicate the result of increased learning centralization leading to better performance on the MARL benchmark set from Gupta et al. (2017). We further apply parameter sharing to 8 "more modern" single-agent deep RL (DRL) methods for the first time in the literature. With this, we achieved the best documented performance on a set of MARL benchmarks and achieved up to 38 times more average reward in as little as 7% as many episodes compared to documented parameter sharing arrangement. We finally offer a formal proof of a set of methods that allow parameter sharing to serve in environments with heterogeneous agents.