 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter Efficient Diff Pruning for Bias Mitigation
Paper and Code
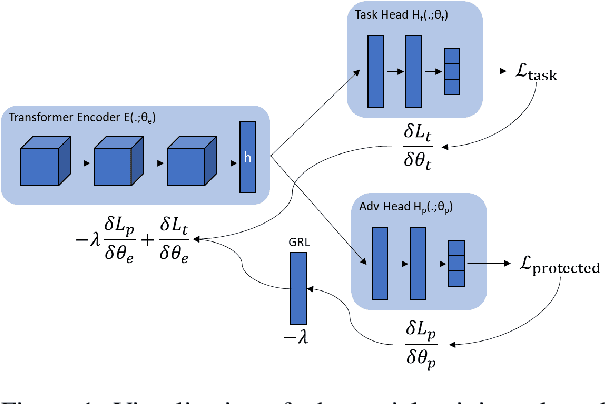
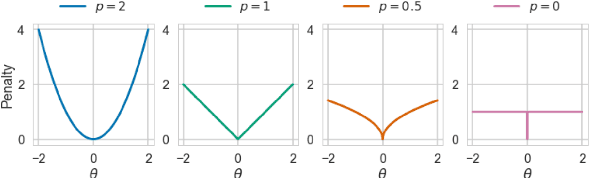
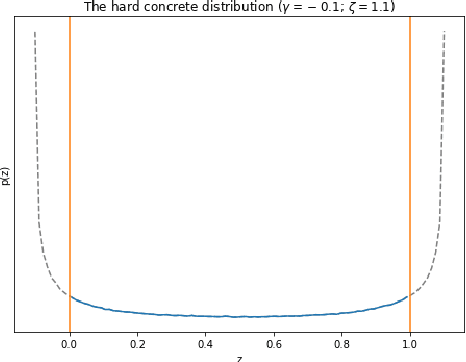
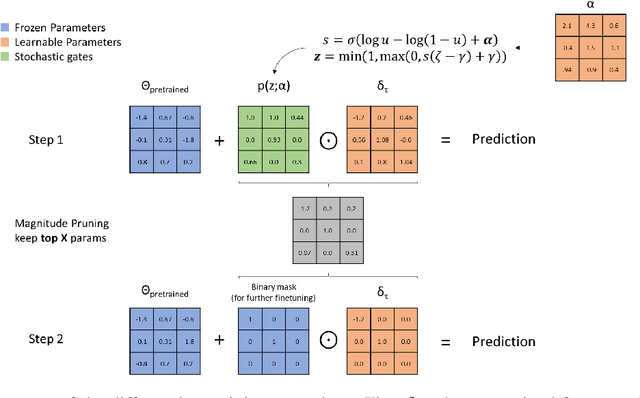
In recent years language models have achieved state of the art performance on a wide variety of natural language processing tasks. As these models are continuously growing in size it becomes increasingly important to explore methods to make them more storage efficient. At the same time their increase cognitive abilities increase the danger that societal bias existing in datasets are implicitly encoded in the model weights. We propose an architecture which deals with these two challenges at the same time using two techniques: DiffPruning and Adverserial Training. The result is a modular architecture which extends the original DiffPurning setup with and additional sparse subnetwork applied as a mask to diminish the effects of a predefined protected attribute at inference time.