 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallelizing Exploration-Exploitation Tradeoffs with Gaussian Process Bandit Optimization
Paper and Code
Jun 27, 2012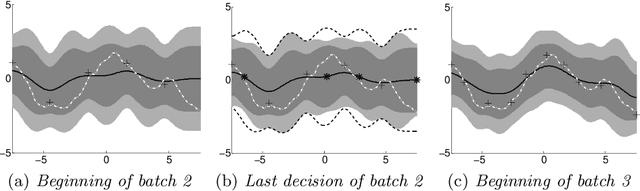
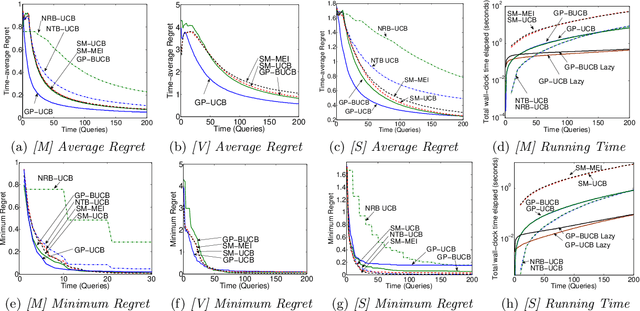


Can one parallelize complex exploration exploitation tradeoffs? As an example, consider the problem of optimal high-throughput experimental design, where we wish to sequentially design batches of experiments in order to simultaneously learn a surrogate function mapping stimulus to response and identify the maximum of the function. We formalize the task as a multi-armed bandit problem, where the unknown payoff function is sampled from a Gaussian process (GP), and instead of a single arm, in each round we pull a batch of several arms in parallel. We develop GP-BUCB, a principled algorithm for choosing batches, based on the GP-UCB algorithm for sequential GP optimization. We prove a surprising result; as compared to the sequential approach, the cumulative regret of the parallel algorithm only increases by a constant factor independent of the batch size B. Our results provide rigorous theoretical support for exploiting parallelism in Bayesian global optimization. We demonstrate the effectiveness of our approach on two real-world applications.