Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverprotective Training Environments Fall Short at Testing Time: Let Models Contribute to Their Own Training
Paper and Code
Mar 30, 2021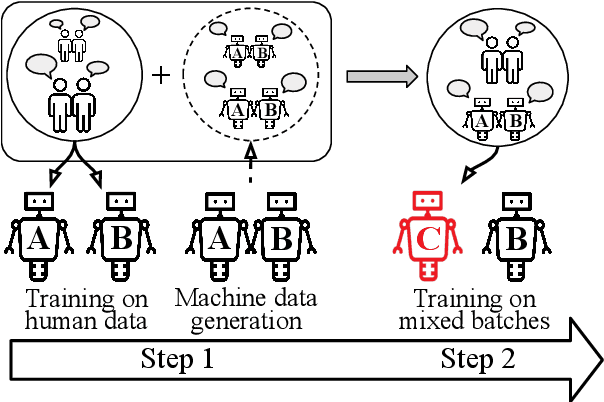
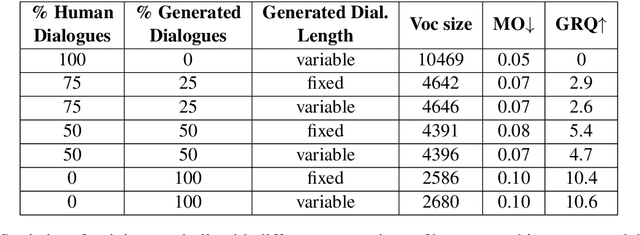


Despite important progress, conversational systems often generate dialogues that sound unnatural to humans. We conjecture that the reason lies in their different training and testing conditions: agents are trained in a controlled "lab" setting but tested in the "wild". During training, they learn to generate an utterance given the human dialogue history. On the other hand, during testing, they must interact with each other, and hence deal with noisy data. We propose to fill this gap by training the model with mixed batches containing both samples of human and machine-generated dialogues. We assess the validity of the proposed method on GuessWhat?!, a visual referential game.
* This paper has been published in the Proceedings of the Seventh
Italian Conference on Computational Linguistics, CLiC-it 2020
View paper on