 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming Catastrophic Interference in Online Reinforcement Learning with Dynamic Self-Organizing Maps
Paper and Code
Oct 29, 2019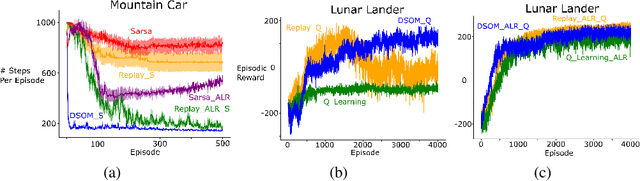
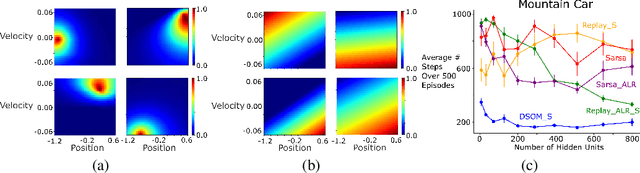
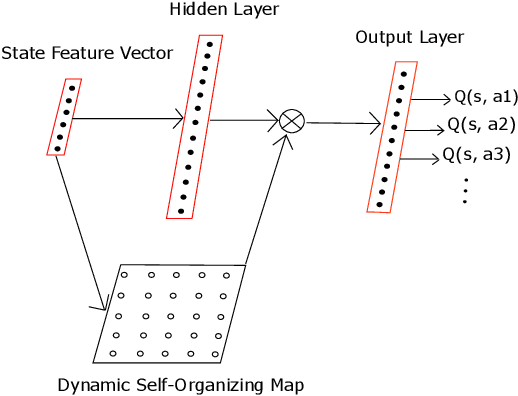
Using neural networks in the reinforcement learning (RL) framework has achieved notable successes. Yet, neural networks tend to forget what they learned in the past, especially when they learn online and fully incrementally, a setting in which the weights are updated after each sample is received and the sample is then discarded. Under this setting, an update can lead to overly global generalization by changing too many weights. The global generalization interferes with what was previously learned and deteriorates performance, a phenomenon known as catastrophic interference. Many previous works use mechanisms such as experience replay (ER) buffers to mitigate interference by performing minibatch updates, ensuring the data distribution is approximately independent-and-identically-distributed (i.i.d.). But using ER would become infeasible in terms of memory as problem complexity increases. Thus, it is crucial to look for more memory-efficient alternatives. Interference can be averted if we replace global updates with more local ones, so only weights responsible for the observed data sample are updated. In this work, we propose the use of dynamic self-organizing map (DSOM) with neural networks to induce such locality in the updates without ER buffers. Our method learns a DSOM to produce a mask to reweigh each hidden unit's output, modulating its degree of use. It prevents interference by replacing global updates with local ones, conditioned on the agent's state. We validate our method on standard RL benchmarks including Mountain Car and Lunar Lander, where existing methods often fail to learn without ER. Empirically, we show that our online and fully incremental method is on par with and in some cases, better than state-of-the-art in terms of final performance and learning speed. We provide visualizations and quantitative measures to show that our method indeed mitigates interference.