 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOracle Analysis of Representations for Deep Open Set Detection
Paper and Code
Sep 22, 2022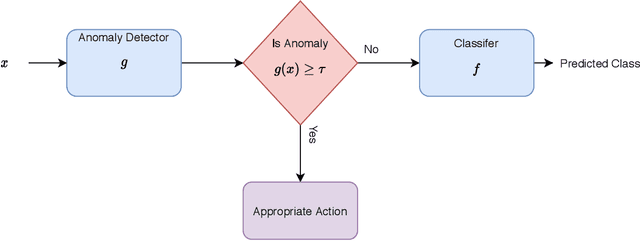
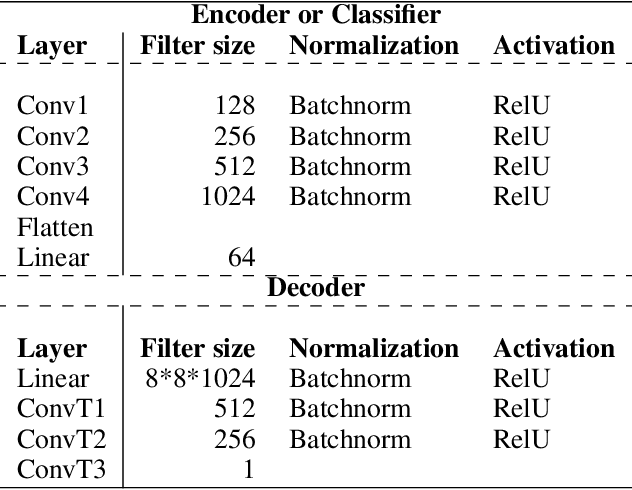
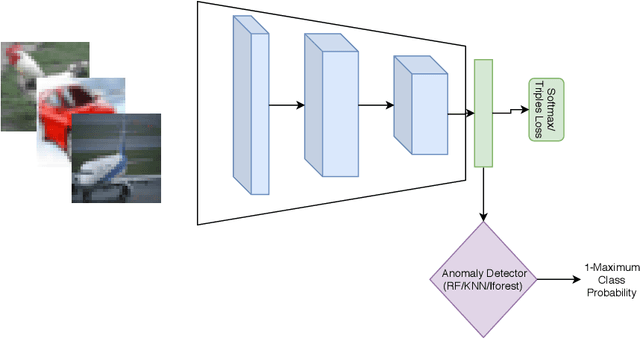
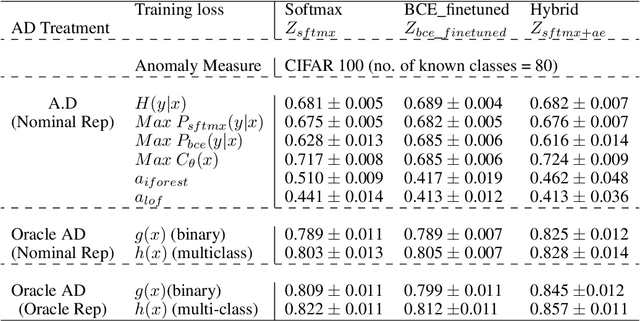
The problem of detecting a novel class at run time is known as Open Set Detection & is important for various real-world applications like medical application, autonomous driving, etc. Open Set Detection within context of deep learning involves solving two problems: (i) Must map the input images into a latent representation that contains enough information to detect the outliers, and (ii) Must learn an anomaly scoring function that can extract this information from the latent representation to identify the anomalies. Research in deep anomaly detection methods has progressed slowly. One reason may be that most papers simultaneously introduce new representation learning techniques and new anomaly scoring approaches. The goal of this work is to improve this methodology by providing ways of separately measuring the effectiveness of the representation learning and anomaly scoring. This work makes two methodological contributions. The first is to introduce the notion of Oracle anomaly detection for quantifying the information available in a learned latent representation. The second is to introduce Oracle representation learning, which produces a representation that is guaranteed to be sufficient for accurate anomaly detection. These two techniques help researchers to separate the quality of the learned representation from the performance of the anomaly scoring mechanism so that they can debug and improve their systems. The methods also provide an upper limit on how much open category detection can be improved through better anomaly scoring mechanisms. The combination of the two oracles gives an upper limit on the performance that any open category detection method could achieve. This work introduces these two oracle techniques and demonstrates their utility by applying them to several leading open category detection methods.