 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimus: Organizing Sentences via Pre-trained Modeling of a Latent Space
Paper and Code
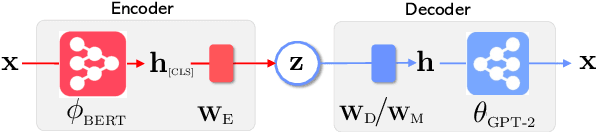



When trained effectively, the Variational Autoencoder (VAE) can be both a powerful generative model and an effective representation learning framework for natural language. In this paper, we propose the first large-scale language VAE model, Optimus. A universal latent embedding space for sentences is first pre-trained on large text corpus, and then fine-tuned for various language generation and understanding tasks. Compared with GPT-2, Optimus enables guided language generation from an abstract level using the latent vectors. Compared with BERT, Optimus can generalize better on low-resource language understanding tasks due to the smooth latent space structure. Extensive experimental results on a wide range of language tasks demonstrate the effectiveness of Optimus. It achieves new state-of-the-art on VAE language modeling benchmarks. We hope that our first pre-trained big VAE language model itself and results can help the NLP community renew the interests of deep generative models in the era of large-scale pre-training, and make these principled methods more practical.