 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Anchor-based Detectors for Autonomous Driving Scenes
Paper and Code
Aug 11, 2022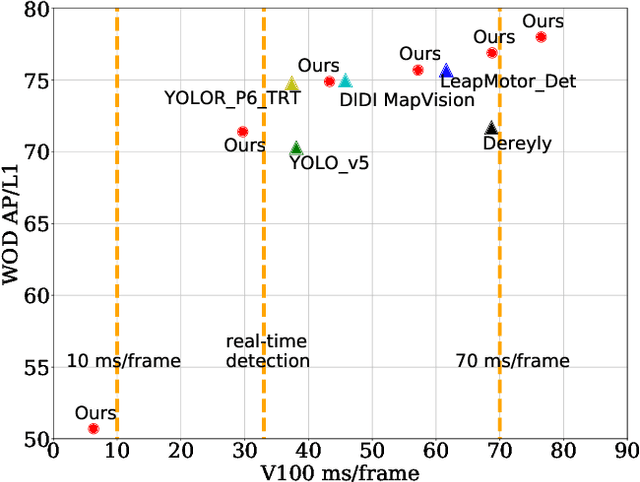
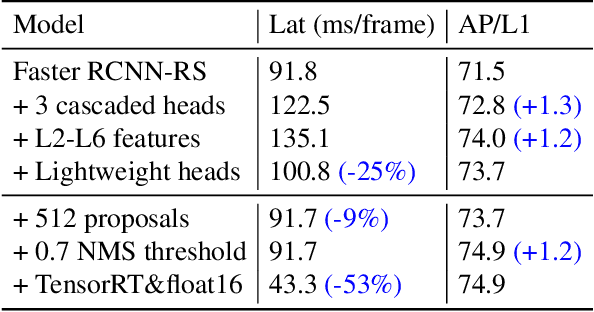
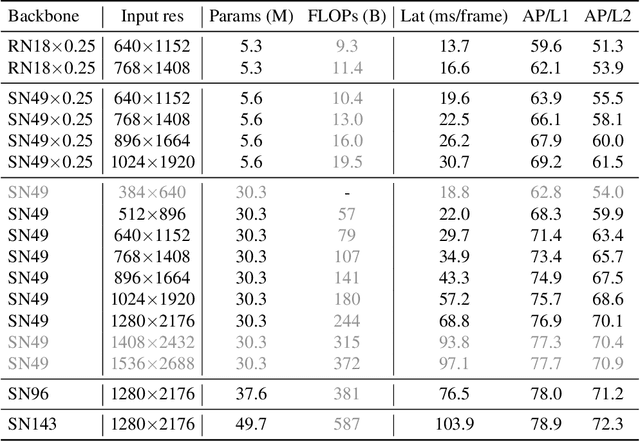
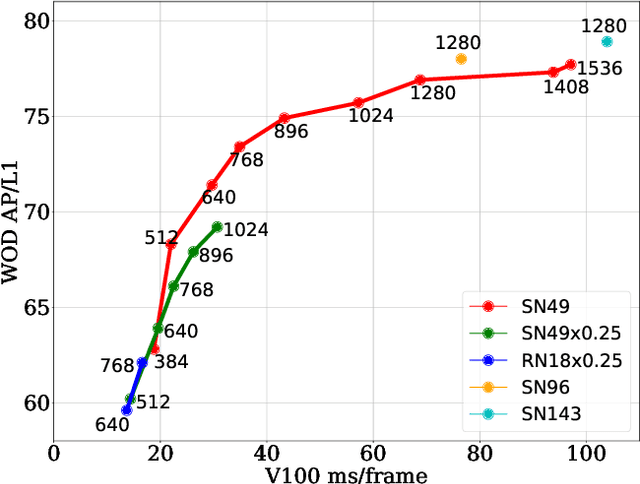
This paper summarizes model improvements and inference-time optimizations for the popular anchor-based detectors in the scenes of autonomous driving. Based on the high-performing RCNN-RS and RetinaNet-RS detection frameworks designed for common detection scenes, we study a set of framework improvements to adapt the detectors to better detect small objects in crowd scenes. Then, we propose a model scaling strategy by scaling input resolution and model size to achieve a better speed-accuracy trade-off curve. We evaluate our family of models on the real-time 2D detection track of the Waymo Open Dataset (WOD). Within the 70 ms/frame latency constraint on a V100 GPU, our largest Cascade RCNN-RS model achieves 76.9% AP/L1 and 70.1% AP/L2, attaining the new state-of-the-art on WOD real-time 2D detection. Our fastest RetinaNet-RS model achieves 6.3 ms/frame while maintaining a reasonable detection precision at 50.7% AP/L1 and 42.9% AP/L2.