 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimization of Speaker Extraction Neural Network with Magnitude and Temporal Spectrum Approximation Loss
Paper and Code
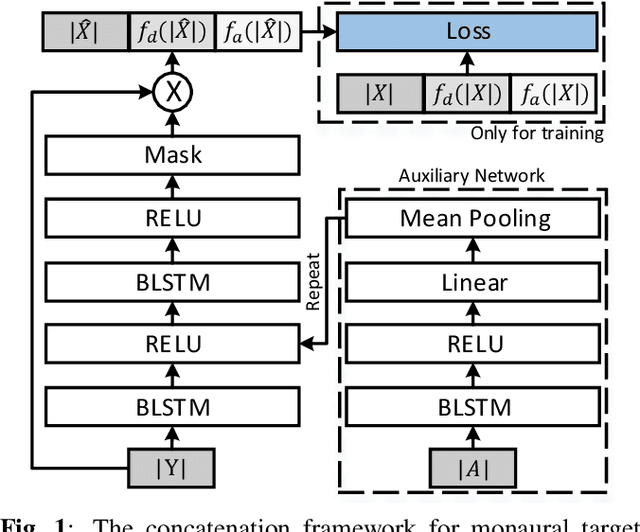
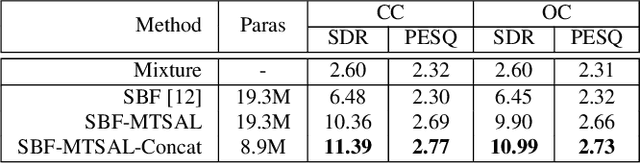
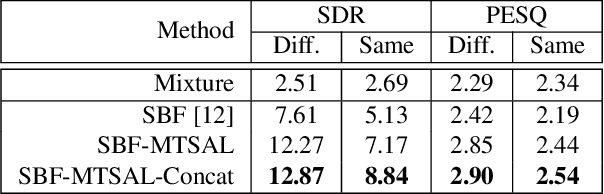
The SpeakerBeam-FE (SBF) method is proposed for speaker extraction. It attempts to overcome the problem of unknown number of speakers in an audio recording during source separation. The mask approximation loss of SBF is sub-optimal, which doesn't calculate direct signal reconstruction error and consider the speech context. To address these problems, this paper proposes a magnitude and temporal spectrum approximation loss to estimate a phase sensitive mask for the target speaker with the speaker characteristics. Moreover, this paper explores a concatenation framework instead of the context adaptive deep neural network in the SBF method to encode a speaker embedding into the mask estimation network. Experimental results under open evaluation condition show that the proposed method achieves 70.4% and 17.7% relative improvement over the SBF baseline on signal-to-distortion ratio (SDR) and perceptual evaluation of speech quality (PESQ), respectively. A further analysis demonstrates 69.1% and 72.3% relative SDR improvements obtained by the proposed method for different and same gender mixtures.