Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Ratio for Data Splitting
Paper and Code
Feb 07, 2022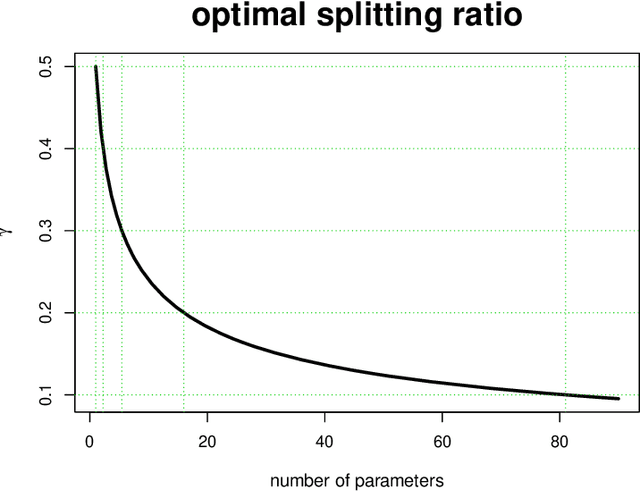



It is common to split a dataset into training and testing sets before fitting a statistical or machine learning model. However, there is no clear guidance on how much data should be used for training and testing. In this article we show that the optimal splitting ratio is $\sqrt{p}:1$, where $p$ is the number of parameters in a linear regression model that explains the data well.
View paper on