 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Preconditioning and Fisher Adaptive Langevin Sampling
Paper and Code
May 23, 2023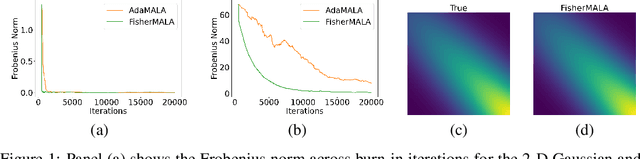
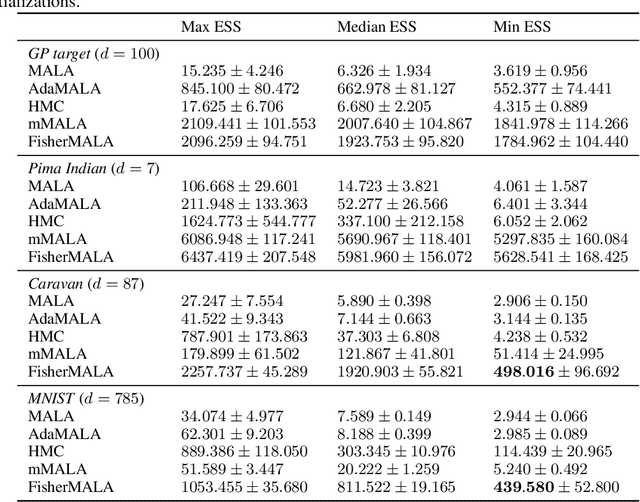
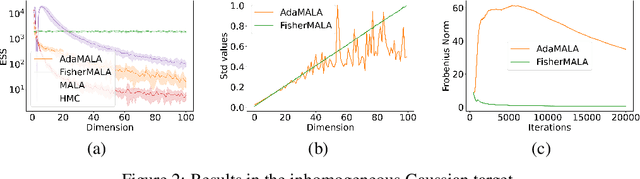
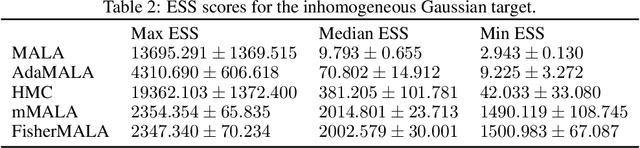
We define an optimal preconditioning for the Langevin diffusion by analytically maximizing the expected squared jumped distance. This yields as the optimal preconditioning an inverse Fisher information covariance matrix, where the covariance matrix is computed as the outer product of log target gradients averaged under the target. We apply this result to the Metropolis adjusted Langevin algorithm (MALA) and derive a computationally efficient adaptive MCMC scheme that learns the preconditioning from the history of gradients produced as the algorithm runs. We show in several experiments that the proposed algorithm is very robust in high dimensions and significantly outperforms other methods, including a closely related adaptive MALA scheme that learns the preconditioning with standard adaptive MCMC as well as the position-dependent Riemannian manifold MALA sampler.