 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Dynamic Regret in Exp-Concave Online Learning
Paper and Code
Apr 23, 2021
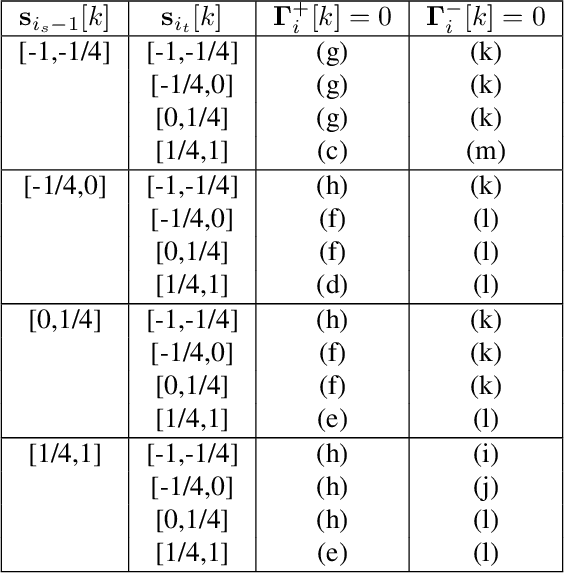
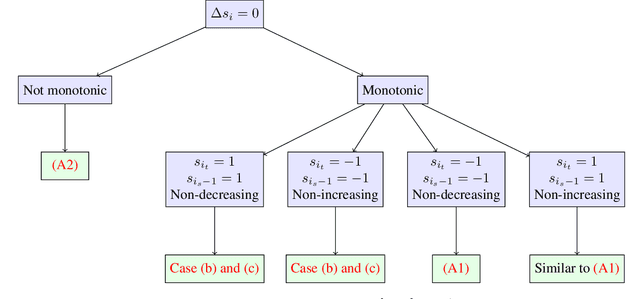
We consider the problem of the Zinkevich (2003)-style dynamic regret minimization in online learning with exp-concave losses. We show that whenever improper learning is allowed, a Strongly Adaptive online learner achieves the dynamic regret of $\tilde O(d^{3.5}n^{1/3}C_n^{2/3} \vee d\log n)$ where $C_n$ is the total variation (a.k.a. path length) of the an arbitrary sequence of comparators that may not be known to the learner ahead of time. Achieving this rate was highly nontrivial even for squared losses in 1D where the best known upper bound was $O(\sqrt{nC_n} \vee \log n)$ (Yuan and Lamperski, 2019). Our new proof techniques make elegant use of the intricate structures of the primal and dual variables imposed by the KKT conditions and could be of independent interest. Finally, we apply our results to the classical statistical problem of locally adaptive non-parametric regression (Mammen, 1991; Donoho and Johnstone, 1998) and obtain a stronger and more flexible algorithm that do not require any statistical assumptions or any hyperparameter tuning.