 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Decision-Making in Mixed-Agent Partially Observable Stochastic Environments via Reinforcement Learning
Paper and Code
Jan 04, 2019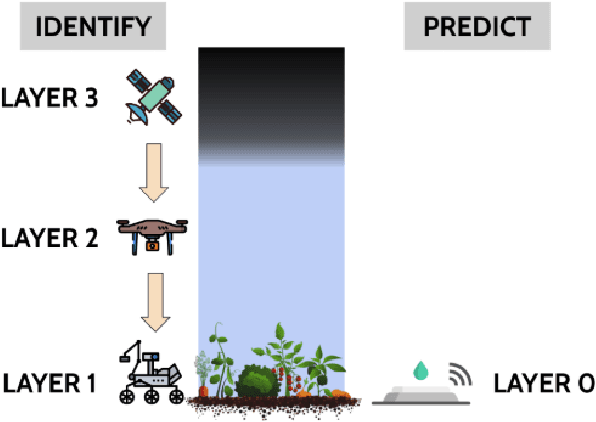
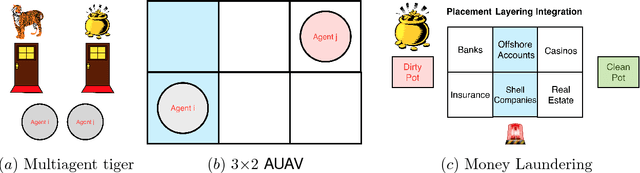


Optimal decision making with limited or no information in stochastic environments where multiple agents interact is a challenging topic in the realm of artificial intelligence. Reinforcement learning (RL) is a popular approach for arriving at optimal strategies by predicating stimuli, such as the reward for following a strategy, on experience. RL is heavily explored in the single-agent context, but is a nascent concept in multiagent problems. To this end, I propose several principled model-free and partially model-based reinforcement learning approaches for several multiagent settings. In the realm of normative reinforcement learning, I introduce scalable extensions to Monte Carlo exploring starts for partially observable Markov Decision Processes (POMDP), dubbed MCES-P, where I expand the theory and algorithm to the multiagent setting. I first examine MCES-P with probably approximately correct (PAC) bounds in the context of multiagent setting, showing MCESP+PAC holds in the presence of other agents. I then propose a more sample-efficient methodology for antagonistic settings, MCESIP+PAC. For cooperative settings, I extend MCES-P to the Multiagent POMDP, dubbed MCESMP+PAC. I then explore the use of reinforcement learning as a methodology in searching for optima in realistic and latent model environments. First, I explore a parameterized Q-learning approach in modeling humans learning to reason in an uncertain, multiagent environment. Next, I propose an implementation of MCES-P, along with image segmentation, to create an adaptive team-based reinforcement learning technique to positively identify the presence of phenotypically-expressed water and pathogen stress in crop fields.